











![Series [CA]: Phần 2 Create SAN Certificate](https://phuongit.com/wp-content/uploads/2024/10/San-Cert.png)
Mở Đầu
Đứng trước bài toán tuyển dụng nhân sự hiện nay, các công ty, doanh nghiệp nói chung, đặc biệt là các công ty về công nghệ thông tin với công tác tuyển dụng nhân sự là việc mang tính chất chiến lược và được thực hiện rất thường xuyên, liên tục để đáp ứng yêu cầu công việc hiện tại và mở rộng quy mô tương lai.
Tuy nhiên, với hàng trăm hồ sơ nộp vào mỗi vị trí tuyển dụng, việc sàng lọc và chọn ra những hồ sơ ứng viên có tìm năng không phải là một công việc dễ dàng. Đứng trước bài toán này, việc ứng dụng một phương pháp khai phá dữ liệu để giải quyết bài toán thực tế đó là rất cần thiết giúp hỗ trợ việc ra quyết định tuyển dụng nhân sự dựa trên cơ sở dữ liệu lịch sử trước đây.
Cây Quyết Định Trong Tuyển Dụng Nhân Sự
Sơ Lược Về Cây Quyết Định
Cuối những năm 70 đầu những năm 80, J.Ross Quinlan đã phát triển một thuật toán sinh cây quyết định. Đây là một tiếp cận tham lam, trong đó nó xác định một cây quyết định được xây dựng từ trên xuống một cách đệ quy theo hướng chia để trị. Hầu hết các thuật toán sinh cây quyết định đều dựa trên tiếp cận top- down trình bày sau đây, trong đó nó bắt đầu từ một tập các bộ huấn luyện và các nhãn phân lớp của chúng. Tập huấn luyện được chia nhỏ một các đệ quy thành các tập con trong quá trình cây được xây dựng.
Cây quyết định là một mô tả tri thức dạng đơn giản nhằm phân các đối tượng dữ liệu thành một số lớp nhất định. Các nút của cây được gán nhãn là tên của các thuộc tính, các cạnh được gán các giá trị có thể của các thuộc tính, các lá mô tả các lớp khác nhau. Các đối tượng được phân lớp theo các đường đi trên cây, qua các cạnh tương ứng với giá trị của thuộc tính của đối tượng tới lá.
Thuật toán cây quyết định
Cây quyết định là cấu trúc phân cấp của các nút và các nhánh có tính chất sau:
Root (Gốc): Là nút trên cùng của cây.
Node trong: nút trung gian trên một thuộc tính đơn (hình Oval).
Nhánh: Biểu diễn các kết quả của kiểm tra trên nút.
Node lá: Biểu diễn lớp hay sự phân phối lớp (hình vuông hoặc chữ nhật)
Phương pháp dựng cây quyết định
Để xây dựng cây quyết định, thực hiện các bước sau đây với các bước được lặp dưới đây:
While()
Bước 1: Chọn A ⇐ thuộc tính quyết định “tốt nhất” cho nút kế tiếp
Bước 2: Gán A là thuộc tính quyết định cho nút
Bước 3: Với mỗi giá trị của A, tạo nhánh con mới của nút
Bước 4: Phân loại các mẫu huấn luyện cho các nút lá
Bước 5: Nếu các mẫu huấn luyện được phân loại hoàn toàn thì ngừng, Ngược lại, lặp với các nút lá mới.
Một số thuật toán xây dựng cây quyết định
Thuật toán ID3
Được phát biểu bởi Quinlan (trường đại học Syney, Australia) và được công bố vào cuối thập niên 70 của thế kỷ 20. Sau đó, thuật toán ID3 được giới thiệu và trình bày trong mục Induction on Decision Trees, Machine learning năm 1986. Quinlan đã khắc phục được hạn chế của thuật toán CLS. ID3 cho cây kết quả tối ưu hơn thuật toán CLS. Khi áp dụng thuật toán ID3 cho cùng một tập dữ liệu đầu vào và thử nhiều lần thì cho cùng một kết quả bởi vì thuộc tính ứng viên ở mỗi bước trong quá trình xây dựng cây được lựa chọn trước. Tuy nhiên thuật toán này cũng chưa giải quyết được về vấn đề thuộc tính số, liên tục, số lượng các thuộc tính còn bị hạn chế và ID3 làm việc không hiệu quả với dữ liệu bị nhiễu hoặc bị thiếu.
Thuật toán ID3 xây dựng cây quyết định dựa vào sự phân lớp các đối tượng (mẫu huấn luyện) bằng cách kiểm tra giá trị các thuộc tính. ID3 xây dựng cây quyết định từ trên xuống (top -down) bắt đầu từ một tập các đối tượng và các thuộc tính của nó. Tại mỗi nút của cây, tiến hành việc kiểm tra các thuộc tính để tìm ra thuộc tính tốt nhất được sử dụng để phân chia tập các đối tượng mẫu, theo các giá trị của thuộc tính được chọn để mở rộng. Quá trình này được thực hiện một cách đệ quy cho đến khi mọi đối tượng của phân vùng đều thuộc cùng một lớp; lớp đó trở thành nút lá của cây. Để làm được việc này thuật toán ID3 có sử dụng tới hai hàm Entropy và Gain.
Entropy của một tập S được định nghĩa trong Lý thuyết thông tin là số lượng mong đợi các bít cần thiết để mã hóa thông tin về lớp của một thành viên rút ra một cách ngẫu nhiên từ tập S. Trong trường hợp tối ưu, mã có độ dài ngắn nhất. Theo lý thuyết thông tin, mã có độ dài tối ưu là mã gán –log2p bits cho thông điệp có xác suất là p.
Trong trường hợp S là tập ví dụ, thì thành viên của S là một ví dụ, mỗi ví dụ thuộc một lớp hay có một giá trị phân loại.
− Entropy có giá trị nằm trong khoảng [0..1],
− Entropy(S) = 0 <-> tập ví dụ S chỉ toàn ví dụ thuộc cùng một loại, hay S là thuần nhất.
− Entropy(S) = 1 <-> tập ví dụ S có các ví dụ thuộc các loại khác nhau với độ pha trộn là cao nhất.
− 0 < Entropy(S) < 1 <-> tập ví dụ S có số lượng ví dụ thuộc các loại khác nhau là không bằng nhau.
Để đơn giản ta xét trường hợp các ví dụ của S chỉ thuộc loại âm (-) hoặc dương (+)
- p+ là phần các ví dụ dương trong tập
- p- là phần các ví dụ âm trong tập
Khi đó, entropy đo độ pha trộn của tập S theo công thức sau:
Entropy(S)=-p+log2p+ – p–log2p–
Một cách tổng quát hơn, nếu các ví dụ của tập S thuộc nhiều hơn hai loại, giả sử là có c giá trị phân loại thì công thức entropy tổng quát là:
![]()
Trong đó: pi là tỷ lệ mẫu thuộc lớp i trên tập hợp S các mẫu kiểm tra. ID3 được xem là một cải tiến của CLS. Tuy nhiên thuật toán ID3 không có khả năng xử lý đối với những dữ liệu có chứa thuộc tính số – thuộc tính liên tục (numeric attribute) và khó khăn trong việc xử lý các dữ liệu thiếu (missing data) và dữ liệu nhiễu (noisy data). Vấn đề này được giải quyết bởi cải tiến C4.5
Thuật toán C4.5
Để khắc phục những hạn chế của thuật toán ID3, Quinlan đã đưa ra thuật toán C4.5. Thuật toán này có thể phân lớp các dữ liệu có chứa thuộc tính số (hoặc thuộc tính liên tục), thuộc tính đa trị và giải quyết được vấn đề dữ liệu bị nhiễu hoặc bị thiếu. Tuy nhiên C4.5 vẫn có hạn chế đó là làm việc không hiệu quả với những cơ sở dữ liệu rất lớn vì chưa giải quyết được vấn đề bộ nhớ.
Mô tả thuật toán dưới dạng giả mã như sau [1]:
Function xay_dung_cay(T)
{
- <Tính toán tần xuất các giá trị trong các lớp của T>;
- If <Kiểm tra các mẫu, nếu thuộc cùng một lớp hoặc có rất ít mẫu khác lớp>Then <Trả về 1 nút lá>
Else <Tạo một nút quyết định N>;
- For <Với mỗi thuộc tính A> Do <Tính giá trị Gain(A)>;
- <Tại nút N, thực hiện việc kiểm tra để chọn ra thuộc tính có giá trị Gain tốt nhất (lớn nhất). Gọi N.test là thuộc tính có Gain lớn
nhất>;
- If <Nếu test là thuộc tính liên tục> Then <Tìm ngưỡng cho phép tách của N.test>;
- For <Với mỗi tập con T` được tách ra từ tập T> Do ( T` được tách ra theo quy tắc:
- Nếu test là thuộc tính liên tục tách theo ngưỡng ở bước 5
- Nếu test là thuộc tính phân loại rời rạc tách theo các giá trị của thuộc tính này.
)
- { If <Kiểm tra, nếu T’ rỗng>} Then
<Gán nút con này của nút N là nút lá>; Else
- <Gán nút con này là nút được trả về bằng cách gọi đệ qui lại đối với hàm xay_dung_cay(T’), với tập T’>;
}
- <Tính toán các lỗi của nút N>;
<Trả về nút N>;
}
T là tập dữ liệu ban đầu, số lượng mẫu được ký hiệu là |T|. Quá trình xây dựng cây được tiến hành từ trên xuống. Đầu tiên ta xác định nút gốc, sau đó xác định các nhánh xuất phát từ gốc này. Tập T được chia thành các tập con theo các giá trị của thuộc tính được xét tại nút gốc. Nếu T có m thuộc tính thì có m khả năng để lựa chọn thuộc tính. Một số thuật toán thì trong quá trình xây dựng cây mỗi thuộc tính chỉ được xét một lần, nhưng với thuật toán này một thuộc tính có thể được xét nhiều lần.
Xét thuộc tính X có n giá trị lần lượt là L1, L2,..Ln. Khi đó, ta có thể chia tập T ra thành n tập con Xi(i=1..n ) theo các giá trị của X. Tần xuất freq (Cj,T) là số lượng mẫu của tập T nào đó được xếp vào lớp con Cj. Xác xuất để một mẫu được lấy bất kỳ từ T thuộc lớp Cj là:
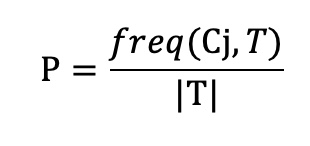
Khi đó Information (T) được tính theo công thức sau:
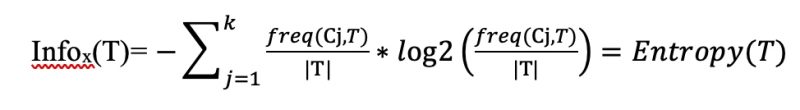
Công thức này đánh giá số lượng thông tin trung bình cần thiết để phân lớp các mẫu trong tập hợp T. Khi đó:
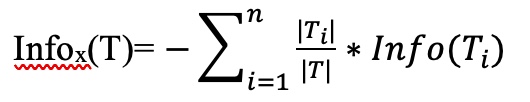
Gain(X, T) = Entropy(T) – Infox(T)
Thuộc tính được lựa chọn tại một nút là thuộc tính có Gain lớn nhất. Thuộc tính được chọn sẽ được dùng để phân lớp tập mẫu dữ liệu tại nút đó. Quá trình phân chia được tiếp tục cho đến khi các mẫu trong tập dữ liệu được phân lớp hoàn toàn.
Thực Nghiệm
Thuộc Tính Tập Dữ Liệu
Với mỗi hồ sơ ứng viên tuyển dụng sẽ bao gồm 06 thuộc tính, trong đó có 05 thuộc tính chính quan trọng ảnh hưởng tới quyết định tuyển dụng của ứng viên và 01 thuộc tính cho biết kết quả ứng viên có được tuyển dụng hay không. Chi tiết các thuộc tính của ứng viên mô tả ở bảng dưới đây:
| STT | Tên thuộc tính | Giá trị thuộc tính | Ý nghĩa thuộc tính |
| 1 | Trình độ học vấn | Đại học, cao đẳng, trung tâm tin học | Cho biết trình độ học vấn của ứng viên |
| 2 | Tình trạng công việc hiện tại | Đang làm, đang tìm việc | Cho biết ứng viên hiện đang đi làm hay không? |
| 3 | N_Công ty ứng tuyển | 0,1,2,… | Cho biết số lượng công ty mà ứng viên đã từng làm. |
| 4 | Trường Top đào tạo | Yes, No | Cho biết trường mà ứng viên được đào tạo nằm trong số các trường hàng đầu về CNTT hay không |
| 5 | Đã tham gia dự án | Yes, No | Cho biết ứng viên đã tham gia dự án thực tế liên quan hay không? |
| 6 | Kết quả tuyển dụng | Yes, No | Cho biết kết quả ứng viên được tuyển dụng (Yes) hay không được tuyển dụng (No). |
Bảng 1: Tập thuộc tính dữ liệu thử nghiệm
Tập Dữ Liệu Mẫu
Tập dữ liệu thực hiện trong báo cáo này là 522 bản ghi
| STT | ID_hồ sơ | Trình độ học vấn | Tình trạng công việc hiện tại | N_Công ty ứng tuyển | Trường top đào tạo | Dự án tham giá | Kết quả tuyển dụng |
| 1 | 170 | Đại học | Đang làm | 2 | No | No | Yes |
| 2 | 217 | Đại học | Đang tìm việc | 1 | Yes | Yes | Yes |
| 3 | 222 | Cao đẳng | Đang tìm việc | 4 | No | No | No |
| 4 | 310 | Đại học | Đang làm | 1 | Yes | No | Yes |
| 5 | 343 | Đại học | Đang làm | 5 | Yes | No | Yes |
| 6 | 356 | Đại học | Đang tìm việc | 1 | Yes | Yes | Yes |
| 7 | 432 | Cao đẳng | Đang làm | 0 | No | No | No |
| 8 | 477 | Đại học | Đang tìm việc | 6 | No | Yes | Yes |
| 9 | 489 | Trung tâm tin học | Đang làm | 2 | No | Yes | Yes |
| 10 | 490 | Cao đẳng | Đang tìm việc | 3 | No | No | No |
| 11 | 551 | Đại học | Đang tìm việc | 0 | Yes | No | Yes |
| 12 | 563 | Trung tâm tin học | Đang làm | 3 | No | Yes | Yes |
| 13 | 642 | Đại học | Đang tìm việc | 0 | No | No | No |
Bảng 2: Tập dữ liệu mẫu thử nghiệm
Phương Pháp Đánh Giá
Tính hiệu quả của giải thuật được đánh giá bởi chỉ số khôi phục (Recall), tỉ lệ chính xác (Precision), và hệ số điều hòa F-measure. Trong đó:
- TP – True Positives: Tổng số ứng viên dự đoán đúng là được phỏng vấn
- TN – True Negatives: Tổng số ứng viên dự đoán đúng là không được phỏng vấn
- FP – False Positives: Tổng số ứng viên dự đoán là được phỏng vấn nhưng thực tế không được phỏng vấn.
- FN – False Negatives: Tổng số ứng viên dự đoán là không được phỏng vấn như thực tế là được phỏng vấn.
Một thuật toán hoàn hảo khi nó phát hiện tất cả các trường hợp ứng viên được phỏng vấn và không được phỏng vấn và không có nhầm lẫn nào, tương ứng với chỉ số khôi phục bằng 100% và độ chính xác cũng đạt 100%. Tuy nhiên thực tế rất khó để đạt được kết quả đó. Trong trường hợp điều chỉnh ngưỡng theo chiều hướng ít khắt khe hơn, độ khôi phục sẽ được cải thiện nhưng đồng thời làm giảm độ chính xác. Ở chiều ngược lại, nếu tăng mức độ khắt khe thì có thể làm tăng độ chính xác nhưng sẽ dẫn đến giảm độ khôi phục. Việc sử dụng hệ số điều hoà được tính từ tỉ lệ khôi phục và tỉ lệ chính xác cho phép đánh giá hiệu quả của phương thức một cách hợp lý với sự hài hoà giữa hai tiêu chí trên.
Thực Nghiệm Với Weka
Weka là một công cụ phần mềm viết bằng Java phục vụ lĩnh vực học máy và khai phá dữ liệu.
Các tính năng chính:
- Một tập các công cụ tiền xử lý dữ liệu, các giải thuật học máy, khai phá dữ liệu và các phương pháp thí nghiệm đánh giá.
- Giao diện đồ họa( gồm cả tính năng hiển thị hóa dữ liệu)
- Môi trường cho phép so sánh các giải thuật khi học máy và khai phá dữ liệu
Thực hiện tải phần mềm tại đây
Giao diện phần mềm sau khi cài đặt hoàn thành

Hình 1: Giao diện phần mềm Weka
Thực hiện cài đặt thêm các gói thư viện và thuật toàn, chọn Tools -> Package manager
Hình 2: Thư viện phần mềm Weka
Chọn Available để cài đặt các gói
Để cài đặt thuật toán ID3, cần cài đặt gói simpleEducationLearningSchemes
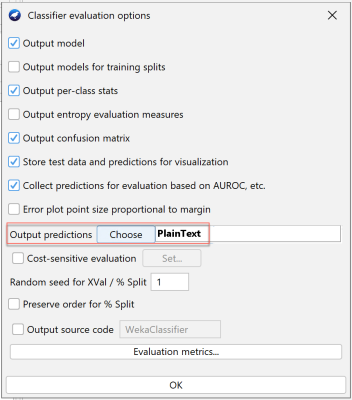
Hình 4: Cầu hình đầu output cho việc dự đoán
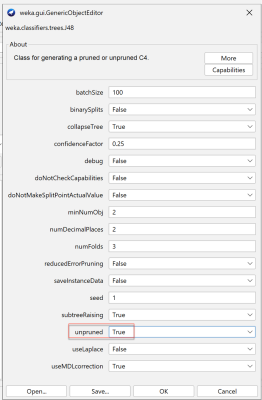
Hình 5: Tham số cấu hình cho thuật toán J48
Tiền xử lí dữ liệu
Giai đoạn 1: Loại bỏ các dữ liệu dư thừa và chuẩn hóa khuôn dạng dữ liệu để WEKA có thể đọc được tập tin dữ liệu “.csv”. Cụ thể:
| STT | ID_ho so | Trinh do hoc van | Tinh trang cong viec | N_Cong ty ung tuyen | Truong top dao tao | Du an tham gia | Ket qua tuyen dung |
| 1 | 170 | Dai hoc | dang lam | 2 | No | No | Yes |
| 2 | 217 | Dai hoc | dang tim viec | 1 | Yes | Yes | Yes |
| 3 | 222 | Cao dang | dang tim viec | 4 | No | No | No |
| 4 | 310 | Dai hoc | dang lam | 1 | Yes | No | Yes |
| 5 | 343 | Dai hoc | dang lam | 5 | Yes | No | Yes |
| 6 | 356 | Dai hoc | dang tim viec | 1 | Yes | Yes | Yes |
| 7 | 432 | Cao dang | dang lam | 0 | No | No | No |
| 8 | 477 | Dai hoc | dang tim viec | 6 | No | Yes | Yes |
| 9 | 489 | trung tam tin hoc | dang lam | 2 | No | Yes | Yes |
| 10 | 490 | Cao dang | dang tim viec | 3 | No | No | No |
| 11 | 551 | Dai hoc | dang tim viec | 0 | Yes | No | Yes |
| 12 | 563 | trung tam tin hoc | dang lam | 3 | No | Yes | Yes |
| 13 | 642 | Dai hoc | dang tim viec | 0 | No | No | No |
| 14 | 647 | trung tam tin hoc | dang lam | 4 | No | No | No |
| 15 | 659 | Cao dang | dang tim viec | 5 | No | Yes | Yes |
| 16 | 660 | Dai hoc | dang lam | 2 | Yes | No | Yes |
| 17 | 672 | Cao dang | dang lam | 0 | No | No | No |
| 18 | 676 | Dai hoc | dang tim viec | 4 | No | Yes | Yes |
| 19 | 680 | Cao dang | dang tim viec | 4 | No | No | No |
| 20 | 681 | trung tam tin hoc | dang lam | 2 | No | Yes | Yes |
Bảng 3: Dữ liệu sau khi tiền xử lý
Giai đoạn tiền xử lý này, xử dụng công cụ excel hoặc các công cụ hỗ trợ bỏ dấu tiếng việt để tự động đọc dữ liệu từ tập tin dữ liệu ban đầu, xử lý các giá trị của từng dòng dữ liệu và ghi dữ liệu vào một tập tin mới.
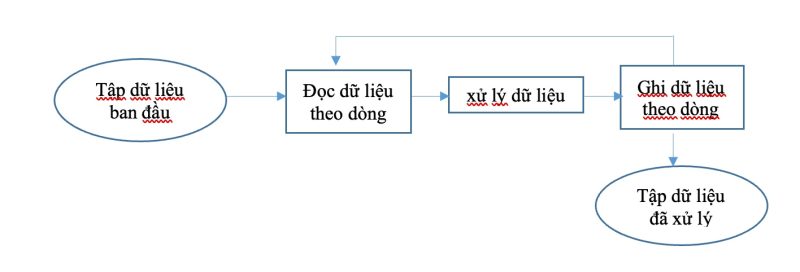
Hình 6: Quá trình tiền xử lý dữ liệu
Kết thúc giai đoạn 1, tập tin dữ liệu có 6 thuộc tính gồm: STT, ID_ho so, Trinh do hoc van, Tinh trang cong viec, N_Cong ty ung tuyen, Truong top dao tao, Du an tham gia, Ket qua tuyen dung.
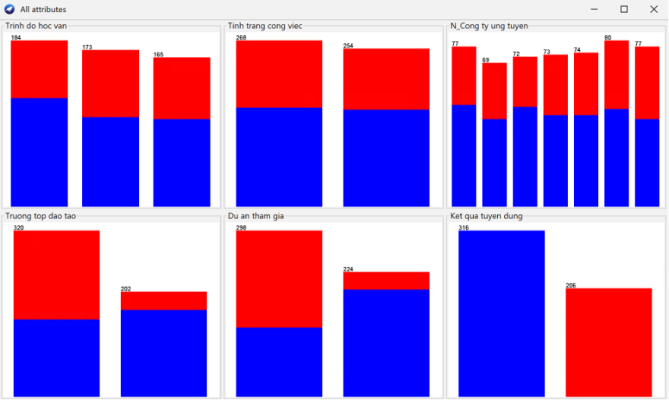
Hình 7: Thống kê các thuộc tính
- Giai đoạn 2: Tiến hành lọc dữ liệu để loại bỏ các bản ghi giống nhau và xử lý các giá trị thiếu (missing value) bằng cách sử dụng các bộ lọc dữ liệu được WEKA cung cấp.
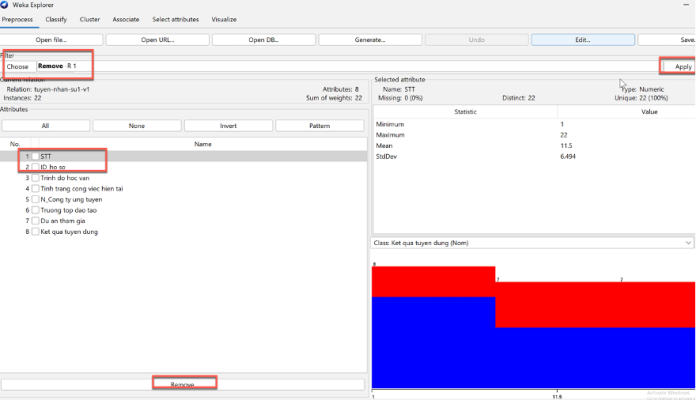
Thực Hiện Thực Nghiệm Với Thuật Toán J48
- Đánh giá hiệu quả phân lớp của thuật toán đối với tập dữ liệu được cho theo 2 phương pháp là Cross-validation và percentage split.
- Cross-validation:
- Một kĩ thuật được sử dụng để kiểu tra hiện xuất của mô hình tiên đoán.Cross-validation tiên đoán sự ăn khớp của một mô hình tới một tập giả thiết hợp lệ (Test set) khi mà ta không có sẵn tập hợp lệ tường minh.
- Một loại cross-validation thường dùng là k-folds cross-validation: Tập mẫu ban đầu được phân chia ngẫu nhiên tới k tập mẫu con. Với k tập mẫu con này, một mẫu đơn được dùng như dữ liệu đánh giá cho việc kiểm tra mô hình, và k-1 tập mẫu còn lại được sử dụng như dữ liệu training. Tiến trình đánh giá chéo được lặp lại k lần ( tham số Folds in weak). Lấy trung bình k kết quả thu được ta có một đánh giá cho mô hình.
- Ưu điểm: việc lặp lại ngẫu nhiêu các mẫu con được sử dụng cho cả training và testing, và đúng một lần.
| Lần chạy | Số Folds | Tổng số bản ghi | Số mẫu phân lớp đúng | Số mẫu phân lớp sai | Tỷ lệ phân lớp đúng | Tỷ lệ phân lớp sai |
| 1 | 10 | 522 | 448 | 74 | 85.82% | 14.18% |
| 2 | 5 | 522 | 447 | 75 | 85.63% | 14.37% |
Bảng 4: Kết quả phân lớp J48 với Folds
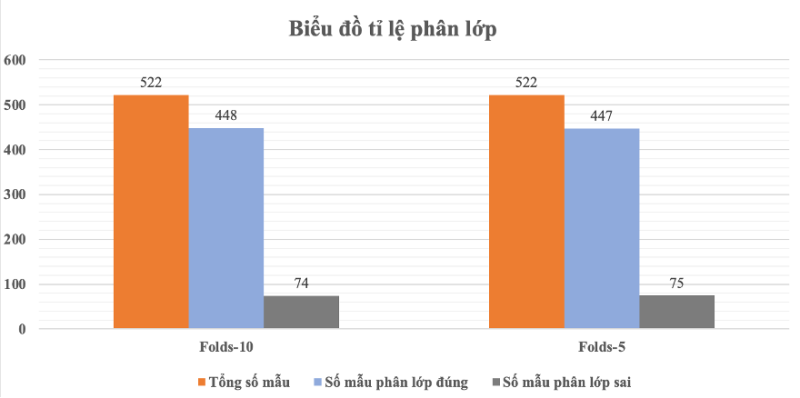
Hình 9: Biểu đồ phân lớp J48 theo Folds
Nhận xét: Qua biểu đồ thấy rằng kết quả chạy phân lớp Folds 10 và Folds 5 kết quả tương đối gần bằng nhau.
- Percentage: Cho biết tỉ lệ phân chia là bao nhiêu % thì đạt hiệu quả phân lớp cao nhất.
- Tỷ lệ phân chia cho biết số mẫu được chọn cho tập huấn luyện và số mẫu được chọn cho tập test.
- Dữ liệu thực nghiệm chia thành 2 phần, huấn luyện và kiểm thử. Tiến hành dùng dữ liệu huấn luyện để tạo mẫu, dùng dữ liệu kiểm thử để dự đoán rồi xác định kết quả được phỏng vấn hay không được phỏng vấn.
Thực nghiệm sẽ tiến hành 05 lần với các tỷ lệ như sau:
- Lần 1: Sử dụng J48 cắt tỉa trên tập dữ liệu với tỷ lệ huấn luyện 40%
- Lần 2: Sử dụng J48 cắt tỉa trên tập dữ liệu với tỷ lệ huấn luyện 66% (giá trị mặc định của Weka)
- Lần 3: Sử dụng J48 cắt tỉa trên tập dữ liệu với tỷ lệ huấn luyện 70%
- Lần 4: Sử dụng J48 cắt tỉa trên tập dữ liệu tỷ lệ huấn luyện 80%
- Lần 5: Sử dụng J48 cắt tỉa trên tập dữ liệu tỷ lệ huấn luyện 90% Kết quả các lần chạy ta có bảng sau
| Lần chạy | Tỷ lệ huấn luyện/ kiểm thử | Tổng số bản ghi | Số mẫu phân lớp đúng | Số mẫu phân lớp sai | Tỷ lệ phân lớp đúng | Tỷ lệ phân lớp sai |
| 1 | 40/60 | 313 | 270 | 43 | 86.26% | 13.74% |
| 2 | 66/34 | 177 | 157 | 20 | 88.7% | 11.3% |
| 3 | 70/30 | 157 | 142 | 15 | 90.45% | 9.55% |
| 4 | 80/20 | 100 | 90 | 10 | 90.38% | 9.62% |
| 5 | 90/10 | 52 | 48 | 4 | 92.3% | 7.7% |
Bảng 5: Kết quả phân lớp J48 với Percentage
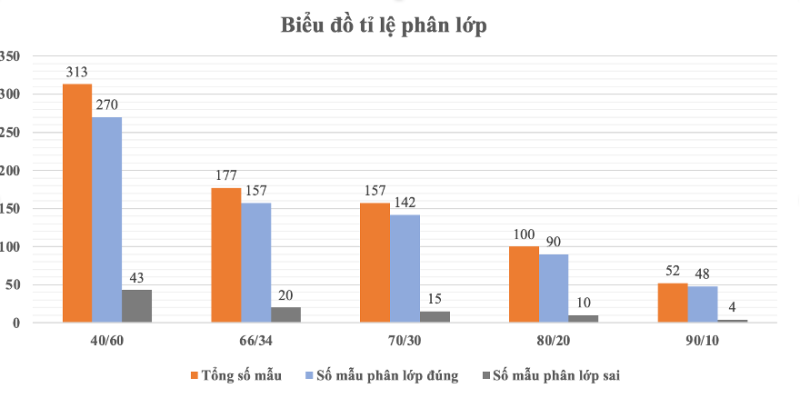
Hình 10: Biểu đồ phân lớp J48 theo Percentage
Thực Hiện Thực Nghiệm Với Thuật Toán JD3
Cross-validation: Chia k-folds như thuật toán J48
| Lần chạy | Số Folds | Tổng số bản ghi | Số mẫu phân lớp đúng | Số mẫu phân lớp sai | Tỷ lệ phân lớp đúng | Tỷ lệ phân lớp sai |
| 1 | 10 | 522 | 436 | 86 | 83.52% | 16.48% |
| 2 | 5 | 522 | 438 | 84 | 83.91% | 16.09% |
Bảng 6: Kết quả phân lớp ID3 với Folds
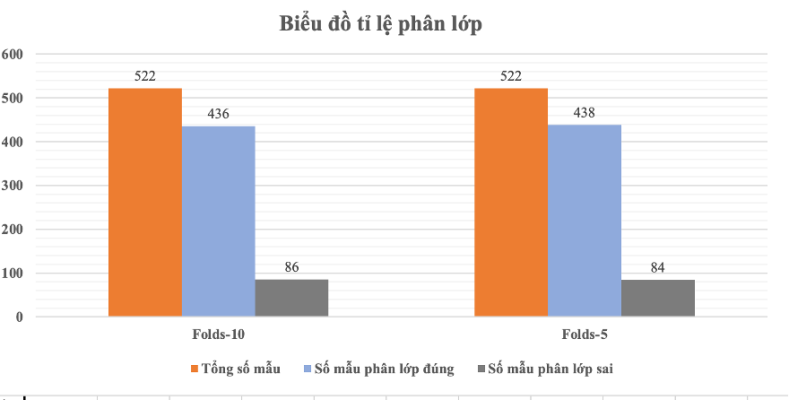
Hình 11: Biểu đồ phân lớp ID3 theo Folds
Percentage: Chia tỉ lệ tập huấn luyện và tập kiểm thử như J48
- Tỷ lệ phân chia cho biết số mẫu được chọn cho tập huấn luyện và số mẫu được chọn cho tập test.
- Dữ liệu thực nghiệm chia thành 2 phần, huấn luyện và kiểm thử. Tiến hành dùng dữ liệu huấn luyện để tạo mẫu, dùng dữ liệu kiểm thử để dự đoán rồi xác định kết quả được phỏng vấn hay không được phỏng vấn.
Thực nghiệm sẽ tiến hành 05 lần với các tỷ lệ như sau:
- Lần 1: Sử dụng ID3 cắt tỉa trên tập dữ liệu với tỷ lệ huấn luyện 40%
- Lần 2: Sử dụng ID3 cắt tỉa trên tập dữ liệu với tỷ lệ huấn luyện 66% (giá trị mặc định của Weka)
- Lần 3: Sử dụng ID3 cắt tỉa trên tập dữ liệu với tỷ lệ huấn luyện 70%
- Lần 4: Sử dụng ID3 cắt tỉa trên tập dữ liệu tỷ lệ huấn luyện 80%
- Lần 5: Sử dụng ID3 cắt tỉa trên tập dữ liệu tỷ lệ huấn luyện 90% Kết quả các lần chạy ta có bảng sau
| Lần chạy | Tỷ lệ huấn luyện/ kiểm thử | Tổng số bản ghi | Số mẫu phân lớp đúng | Số mẫu phân lớp sai | Tỷ lệ phân lớp đúng | Tỷ lệ phân lớp sai |
| 1 | 40/60 | 313 | 231 | 82 | 73.80% | 26.20% |
| 2 | 66/34 | 177 | 149 | 28 | 84.18% | 15.82% |
| 3 | 70/30 | 157 | 135 | 22 | 85.98% | 14.01% |
| 4 | 80/20 | 104 | 91 | 13 | 87.5% | 12.5% |
| 5 | 90/10 | 52 | 47 | 5 | 90.38% | 9.62% |
Bảng 7: Kết quả phân lớp ID3 với Percentage
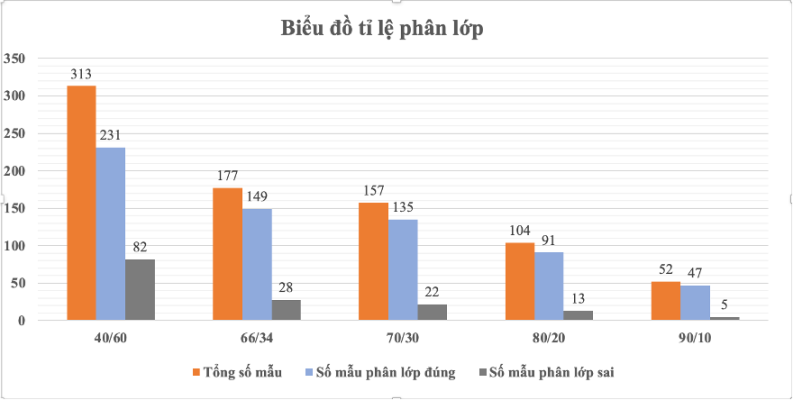
Hình 12: Biểu đồ phân lớp ID3 theo Percentage
So Sánh Kết Quả 2 Thuật Toán
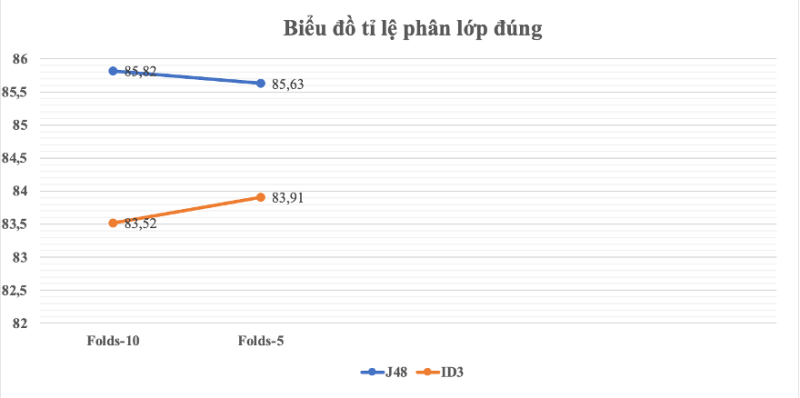
Hình 13: Biểu đồ so sánh phân lớp đúng đánh gia qua Folds
Nhận xét: Với phương pháp phân lớp Folds, cả 2 thuật toán chạy Flods 10 và 5 kết quả không thay đổi nhiều, tuy nhiên thuật toán J48 đạt tỉ lệ phân lớp cao hơn thuật toán ID3
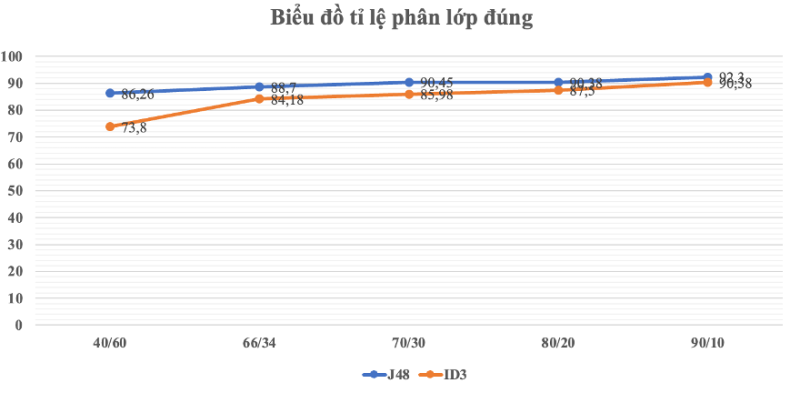
Hình 14: Biểu đồ so sánh phân lớp đúng các thuật toán đánh giá qua Percentage
Nhận xét: Qua kết quả phân lớp của 2 thuật toán J48 và ID3, cả 2 thuật toán đều đạt kết quả phân lớp trên 90% ở tỉ lệ 90% huấn luyện và 10% kiểm thử. Tuy nhiên thuật toán J48 đạt kết quả cao hơn ID3.
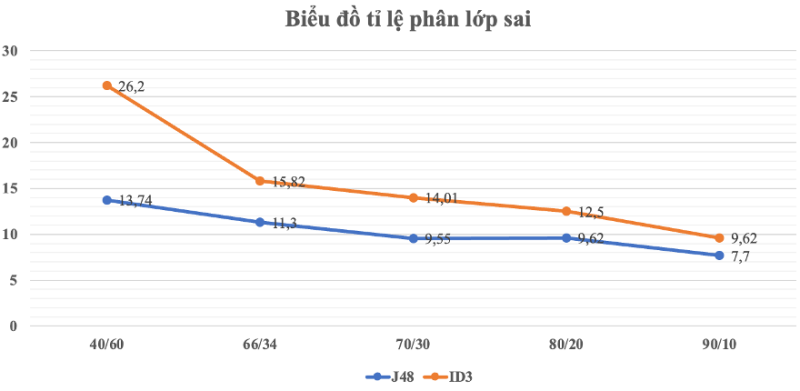
Hình 15: Biểu đồ so sánh phân lớp sai các thuật toán đánh giá qua Percentage
Nhận xét: Qua kết quả phân lớp của 2 thuật toán J48 và ID3, kết quả phân lớp sai lớn nhất ở 40% huấn luyện và 60% kiểm thử, kết quả tốt nhất và sai ít nhất khi tập huấn luyện đạt 90% và 10% kiểm thử.
Kết Quả
Thuật Toán J48
Lần chạy đạt tỷ lệ phân lớp đúng cao nhất
- Giải thuật: J48
- Tỷ lệ dữ liệu huấn luyện: Fold 10
Mô hình cây quyết định được xây dựng:
- Cây quyết định kích cỡ: 16
- Số lượng lá: 9
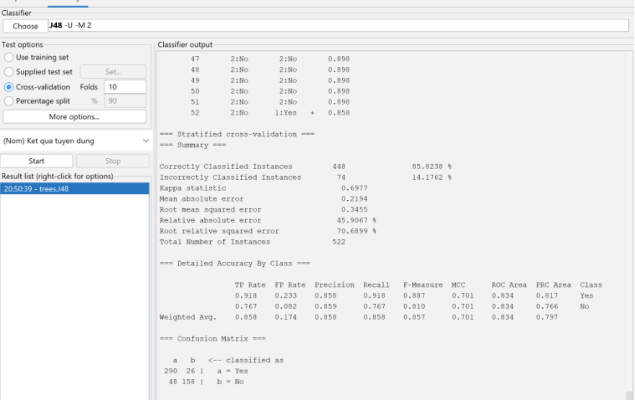
Nhận xét: Ma trận nhầm lẫn J48 (Confusion matrix)
290 mẫu phân lớp đúng ứng viên được chọn
158 mẫu phân lớp đúng ứng viên không được chọn
48 mẫu sai ứng viên không được chọn nhưng phân loại được chọn
26 mẫu sai ứng viên được chọn nhưng phân loại không được chọn
Ý nghĩa các tham số
- TPrate (tỷ lệ mẫu tích cực – Positive)
TP=TP/(TP+FN)
- FPrate (tỷ lệ mẫu tích cực sai)
FP=FP/(FP + TN)
- Precision (Giá trị dự đoán mẫu tích cực đúng):
Precision= TP / (TP + FP)
Recall (Giá trị biểu diễn tỷ lệ mẫu cần thực hiện lại)
- F- measure: Biểu diễn trung bình điều hòa giữa recall và precision
F-measure = 2TP / (2TP + FP + FN)
Cây quyết định sau khi thực hiện chạy với thuật toán J48
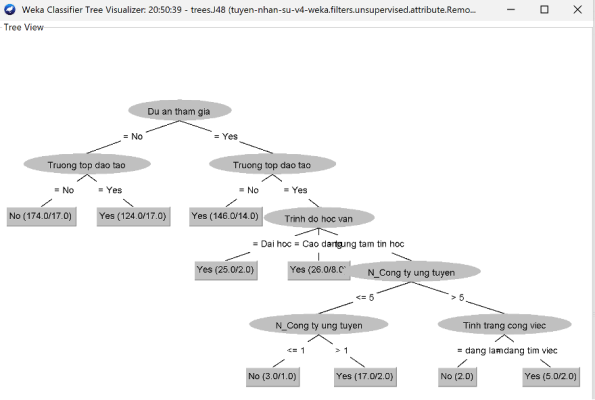
Hình 17: Cây quyết định bài toán phân lớp tuyển nhân sự
Nhận xét: Quy luật cây quyết định cho tuyển nhân sự kết quả như sau:
- Dự án tham gia (No) -> Trường top đào tạo (No) -> No
- Dự án tham gia (No) -> Trường top đào tạo (Yes) -> Yes
- Dự án tham gia (Yes) -> Trường top đào tạo (No) -> Yes
- Dự án tham gia (Yes) -> Trường top đào tạo (No) -> Trình độ học vấn (Đại học) -> Yes
- Dự án tham gia (Yes) -> Trường top đào tạo (No) -> Trình độ học vấn (Cao đẳng) -> Yes
- Dự án tham gia (Yes) -> Trường top đào tạo (No) -> Trình độ học vấn (Trung tâm tin học) -> N_Công ty ứng tuyển (<=5) -> N_Công ty ứng tuyển (<=1) -> No
- Dự án tham gia (Yes) -> Trường top đào tạo (No) -> Trình độ học vấn (Trung tâm tin học) -> N_Công ty ứng tuyển (<=5) -> N_Công ty ứng tuyển (>1) -> Yes
- Dự án tham gia (Yes) -> Trường top đào tạo (No) -> Trình độ học vấn (Trung tâm tin học) -> N_Công ty ứng tuyển (>5) -> Tình trạng công việc(Đang làm) -> No
- Dự án tham gia (Yes) -> Trường top đào tạo (No) -> Trình độ học vấn (Trung tâm tin học) -> (N_Công ty ứng tuyển) -> >5 -> Tình trạng công việc(Đang tìm việc) -> Yes
Thuật Toán ID3
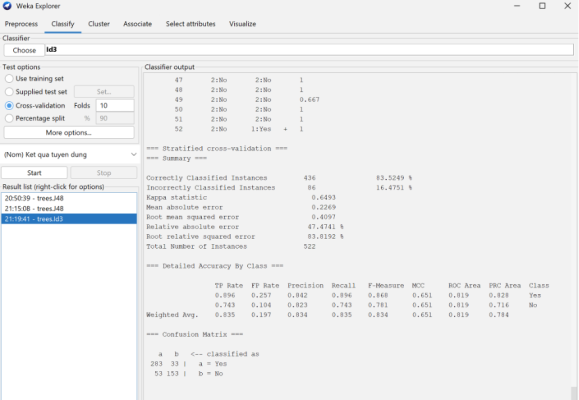
Nhận xét: Ma trận nhầm lẫn ID3 (Confusion matrix)
283 mẫu phân lớp đúng ứng viên được chọn
153 mẫu phân lớp đúng ứng viên không được chọn
53 mẫu sai ứng viên không được chọn nhưng phân loại được chọn
33 mẫu sai ứng viên được chọn nhưng phân loại không được chọn
Kết Luận
Cây quyết định là một mô hình dự đoán được sử dụng phổ biến trong khai phá dữ liệu (Data mining). Trong bài viết này, chúng ta đã tiến hành nghiên cứu và xây dựng, ứng dụng giải thuật cây quyết định, đồng thời sử dụng cây quyết định cho bài toán cụ thế đó là tuyển dụng nhân sự bằng thuật toán ID3 và J48.
Kết quả xây dựng cây quyết định được trình bày một cách trực quan, dễ hiểu và đưa ra quy luật khi có một nhân sự mới cho bộ phận tuyển dụng đánh giá, đưa ra quyết định một cách dễ dàng; Có thể thấy rằng cây quyết định là phương pháp để phân lớp các đối tượng khá hiệu quả và dễ hiểu. Tuy nhiên để đảm bảo hiệu quả cũng như độ tin cậy của cây quyết định thì tập dữ liệu mẫu (Training data) phải đủ lớn và đáng tin cậy khi đó các tập luật được sinh ra mới đủ tốt và hiệu quả. Hi vọng qua bài giúp, giúp các bạn hình dung các thức hoạt động cũng như thuật toán trong giải quyết các bài toàn thực tế. Cùng theo dõi các bài viết tiếp theo về kiến thức công nghệ được cập nhật nhé.