











![Series [CA]: Phần 2 Create SAN Certificate](https://phuongit.com/wp-content/uploads/2024/10/San-Cert.png)
Mở Đầu
Dịch máy song ngữ từ tiếng Anh sang tiếng Việt là một trong những thách thức quan trọng của lĩnh vực xử lý ngôn ngữ tự nhiên (NLP). Đây là một bài toán quan trọng vì nó liên quan đến việc chuyển đổi văn bản và thông tin từ một ngôn ngữ sang một ngôn ngữ khác một cách tự động. Dịch máy tiếng Anh sang tiếng Việt có rất nhiều ứng dụng thực tế, bao gồm việc dịch tài liệu, tin tức, văn bản học thuật, và nhiều lĩnh vực khác.
Bài toán không chỉ đòi hỏi việc hiểu và biểu diễn ngữ nghĩa của văn bản, mà còn đối mặt với những thách thức đặc biệt do sự đa dạng về ngữ cảnh, ngữ pháp, và ngôn ngữ trong cả hai ngôn ngữ. Máy dịch cần phải hiểu ý nghĩa và cách diễn đạt của một câu ở ngôn ngữ nguồn (tiếng Anh) và chuyển nó sang ngôn ngữ đích (tiếng Việt) sao cho bản dịch đảm bảo tính chính xác và hiệu quả trong việc truyền đạt thông điệp.
Để giải quyết bài toán này, nhóm đã nghiên cứu đã áp dụng nhiều phương pháp và kỹ thuật từ lĩnh vực máy học và trí tuệ nhân tạo. Trong thời gian gần đây, mô hình dịch máy dựa trên học sâu và mạng nơ-ron như mô hình Transformer đã đạt được sự nổi bật với khả năng dịch chính xác và tự động hóa cao.
Phân Tích Yêu Cầu
Bài toán yêu cầu xây dựng mô hình dịch máy song ngữ từ ngôn ngữ nguồn sang ngôn ngữ đích với yêu cầu:
- Thu thập và xử lý dữ liệu: Dữ liệu sẽ được thu thập qua các nguồn, sách báo, dataset có sẵn. Sau đó được thực hiện xử lý trước khi đưa vào mô hình học máy
- Xây dựng mô hình dịch máy: Phân tích lựa chọn mô hình phù hợp với bài toán dịch máy, ở đây mô hình dịch song ngữ tiếng anh sang tiếng việt.
- Huấn luyện mô hình và đánh giá: Thực hiện huấn luyện trên một tập dữ liệu lớn chứa các cặp văn bản hoặc câu tiếng Anh và tương ứng tiếng Việt. Dữ liệu này được sử dụng để học cách ánh xạ từ ngôn ngữ nguồn sang ngôn ngữ đích. Đánh giá hiệu suất của mô hình dịch máy sử dụng phương pháp đánh giá như BLEU Score.
Tổng Quan Dịch Máy
Dịch máy (Machine Translation), còn được gọi là dịch tự động, có lịch sử phát triển lâu đời. Khái niệm dịch máy được nhiều tác giả định nghĩa, tuy có một vài điểm khác biệt nhưng hầu hết đều tương đương với định nghĩa sau: Dịch máy là một hệ thống sử dụng máy tính để chuyển đổi văn bản được viết trong ngôn ngữ tự nhiên này thành bản dịch tương ứng trong ngôn ngữ tự nhiên khác.
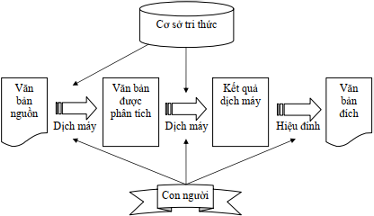
Hình 1: Mô tả hệ thống dịch máy
Hình 1 mô tả hệ thống dịch máy, đầu vào là một văn bản trong ngôn ngữ nguồn, quá trình dịch chia thành hai giai đoạn. Giai đoạn một, văn bản được phân tích thành các thành phần. Giai đoạn hai, các thành phần được dịch thành văn bản ở ngôn ngữ đích. Kết quả dịch có thể được hiệu đính bởi con người để có bản dịch tốt.
Dịch Máy Mạng Nơ-Ron
Kiến trúc encoder – decoder
Đây là kiến trúc đầu tiên của hệ thống dịch máy mạng nơ-ron (NMT), đặt nền móng cho các hệ thống sau này. Kiến trúc này gồm hai thành phần là bộ mã hóa (encoder) và bộ giải mã (decoder), được mô tả như hình.
Hệ dịch NMT sử dụng bộ mã hóa để đọc toàn bộ câu nguồn và mã hóa nó thành một vectơ biểu diễn ý nghĩa của câu. Sau đó, bộ giải mã sử dụng vectơ này để sinh câu dịch tương ứng trong ngôn ngữ đích.
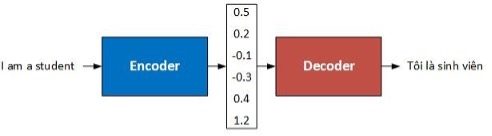
Hình 2: Kiến trúc mã hóa – giải mã (encoder – decoder).
Bộ mã hóa chuyển một câu nguồn thành một vecto có nghĩa, sau đó bộ giải mã sẽ giả mã vecto này để tạo ra bản dịch. Bộ mã hóa và bộ giải mã đều được cấu tạo từ hai lớp RNN cùng chiều chồng lên nhau, ký hiệu < s > và < /s > sử dụng để báo hiệu bắt đầu và kết thúc quá trình giải mã.
Bộ mã hóa đọc câu nguồn là một dãy các vectơ x = (x1, …, xn) một vector c. Phương pháp phổ biến nhất là sử dụng một mạng nơ-ron hồi quy, sao cho:
ht = f (xt, ht−1) (2.2.1.1)
và
c = q(h1, …, hT ) (2.2.1.2)
trong đó, ht là trạng thái ẩn tại thời điểm t, và c là véc tơ ngữ cảnh được sinh ra từ dãy của các trạng thái ẩn. f và q là các hàm phi tuyến.
Bộ giải mã thường được huấn luyện để dự đoán từ tiếp theo yT khi biết véc tơ ngữ cảnh c và tất cả các từ đã được sinh ra trước đó y1, …, yT −1. Nói cách khác, bộ giải mã định nghĩa một xác suất cho câu dịch y bằng cách ước lượng hàm phân phối xác suất có điều kiện sau:
![]() (2.2.1.3)
(2.2.1.3)
trong đó, y = (y1, …, yT ). Với một RNN, mỗi xác suất có điều kiện được mô hình hóa như sau:
p(yt|y1, …, yt−1, c) = g(yt−1, st, c) (2.2.1.4)
Trong đó g là hàm phi tuyến để sinh ra xác suất của yt, và st là trạng thái ẩn của mạng nơ-ron hồi quy, sau này g thường được dùng bởi LSTM. Thông thường một RNN được sử dụng cho cả bộ mã hóa và giải mã.
Kiến trúc transformer
Kiến trúc Transformer được đề xuất bởi nhóm nghiên cứu của Google AI (Vaswani và cộng sự, 2017), có thể coi như là một mô hình mở rộng của mô hình mã hóa – giải mã với attention.
Hai thành phần mã hóa và giải mã trong mô hình Transformer đều sử dụng self-attention nhiều tầng, mã hóa vị trí, các tầng kết nối với nhau toàn bộ (fully connected) như hình:
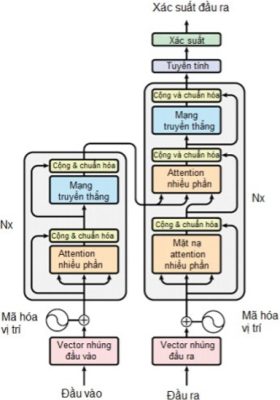
Về cơ bản, bộ mã hóa gồm N tầng giống nhau xếp chồng lên nhau, mỗi tầng có 2 tầng con. Tầng con thứ nhất là cơ chế self-attention nhiều phần (multi-head), tầng con thứ 2 là mạng truyền thẳng đầy đủ (fully connected feed-forward).
Ngoài ra, có thể thêm kĩ thuật kết nối dư (residual connection), theo sau bởi 1 tầng chuẩn hóa (normalization layer). Bộ giải mã cũng gồm N tầng giống nhau xếp chồng. Tại mỗi tầng, bên cạnh 2 tầng con giống như bộ mã hóa, bộ giải mã chèn thêm 1 tầng con ở giữa, cái thể hiện multi-head attention để có thể mô hình khóa được các thông tin cần thiết của câu nguồn tại mỗi thời điểm giải mã.
Đánh giá chất lượng dịch máy
Đánh giá bởi con người
Phương pháp dựa vào con người cho đánh giá tốt nhất đối với chất lượng của bản dịch, tuy nhiên cách đánh giá này mất nhiều thời gian và tốn kém.
Đánh giá tự động BLUE
Độ đo được sử dụng phổ biến để đánh giá tự động chất lượng của dịch máy là BiLingual Evaluation Understudy Score, viết tắt là BLEU, do Papineni đề xuất năm 2002. Ý tưởng chính là so sánh bản dịch tự động với bản dịch chuẩn do người dịch, được xác định dựa trên số lượng n−gram giống nhau giữa bản dịch của câu nguồn với các câu tham chiếu tương ứng, có xét tới yếu tố độ dài của câu, được định nghĩa như công thức:
![]() (2.3.2.1)
(2.3.2.1)
Trong đó:
pi: Giá trị trung bình của độ chính xác n-gram được thay đổi.
wi: Trọng số tích cực.
BP (Brevity Penalty): Phạt ngắn dùng để phạt các bản dịch quá vắn tắt. Phạt ngắn được tính toán trên toàn bộ kho ngữ liệu theo công thức:
![]() (2.3.2.2)
(2.3.2.2)
Trong đó:
c: độ dài của bản dịch.
r: độ dài của kho ngữ liệu tham chiếu.
Điểm BLEU nhận giá trị trong khoảng [0,1] để đo mức độ tương tự của văn bản được dịch bằng máy với tập dữ liệu chất lượng cao do chuyên gia dịch.
Phương Pháp Thực Nghiệm
Mô hình tổng quát cho giải quyết bài toán dịch máy
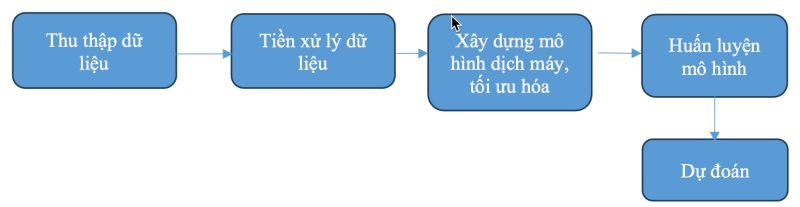
- Thu thập dữ liệu: Bước đầu tiên là thu thập tập dữ liệu song ngữ bao gồm các cặp câu tiếng Anh và tiếng Việt. Dữ liệu này có thể được lấy từ các nguồn như các trang web, tài liệu dịch, sách, văn bản tạp chí, và nguồn dữ liệu tổng hợp khác.
- Tiền xử lý dữ liệu: Sau khi thu thập dữ liệu, cần tiến hành tiền xử lý để làm sạch và chuẩn bị dữ liệu cho việc huấn luyện mô hình. Các bước tiền xử lý bao gồm loại bỏ dấu câu, chuyển đổi văn bản thành chữ thường, tách từ và đánh dấu từng từ bằng mã số, hoặc mã hóa từ.
- Xây dựng mô hình dịch máy: Dịch máy thường sử dụng các mô hình mạng nơ-ron sâu, đặc biệt là kiến trúc Transformer. Mô hình dịch máy này sẽ học cách ánh xạ từ câu tiếng Anh sang câu tiếng Việt. Quá trình này bao gồm việc xây dựng mạng nơ-ron, bao gồm encoder và decoder, cho phép biểu diễn và dịch các câu.
- Tối ưu hóa mô hình: Mô hình dịch máy cần được tối ưu hóa bằng cách sử dụng các thuật toán tối ưu hóa như Adam. Quá trình này giúp cập nhật trọng số của mô hình để cải thiện hiệu suất.
- Huấn luyện mô hình: Dữ liệu tiền xử lý sau cùng sẽ được sử dụng để huấn luyện mô hình. Mô hình sẽ được đưa qua nhiều chu kỳ huấn luyện, với mục tiêu là tối ưu hóa hàm mất mát thông qua việc dự đoán dịch của mô hình và so sánh với dịch thực tế trong tập dữ liệu.
- Dự đoán: Sau khi mô hình được huấn luyện, nó có thể được sử dụng để dự đoán dịch của các câu tiếng Anh mới. Dự đoán này có thể được thực hiện bằng cách đưa câu tiếng Anh vào mô hình và lấy kết quả dịch tiếng Việt.
Đặc Trưng Mô Hình
Embedding layer with position encoding
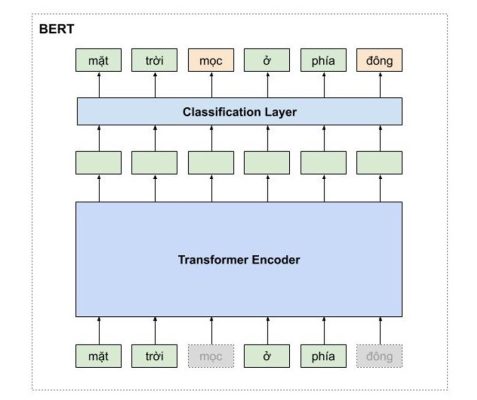
Hình 4: Mô hình transformer encoder
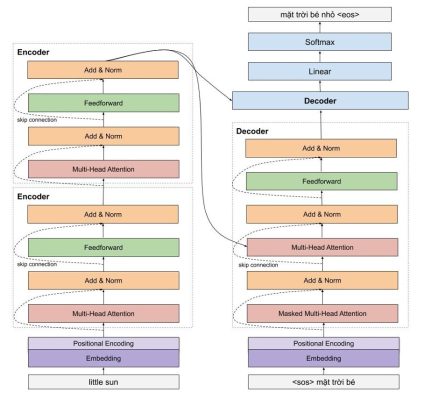
Giống như những mô hình dịch máy khác, kiến trúc tổng quan của mô hình transformer bao gồm 2 phần lớn là encoder và decoder. Encoder dùng để học vector biểu của câu với mong muốn rằng vector này mang thông tin hoàn hảo của câu đó. Decoder thực hiện chức năng chuyển vector biểu diễn kia thành ngôn ngữ đích.
Trong một ví dụ dưới đây, encoder của mô hình transformer nhận một câu tiếng việt, và encode thành một vector biểu diễn ngữ nghĩa của câu little sun, sau đó mô hình decoder nhận vector biểu diễn này, và dịch nó thành câu tiếng việt mặt trời bé nhỏ
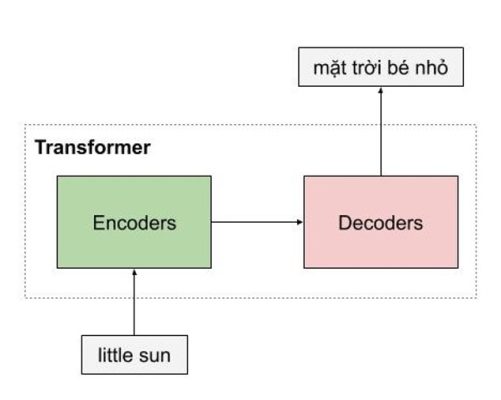
Hình 5: Phân tích câu qua transformer
Một trong những ưu điểm của transformer là mô hình này có khả năng xử lý song song cho các từ. Như hình chúng ta thấy, Encoders của mô hình transfomer là một dạng feedforward neural nets, bao gồm nhiều encoder layer khác, mỗi encoder layer này xử lý đồng thời các từ. Trong khi đó, với mô hình LSTM, thì các từ phải được xử lý tuần tự. Ngoài ra, mô hình Transformer còn xử lý câu đầu vào theo hai hướng mà không cần phải stack thêm một môt hình LSTM nữa như trong kiến trúc Bidirectional LSTM.
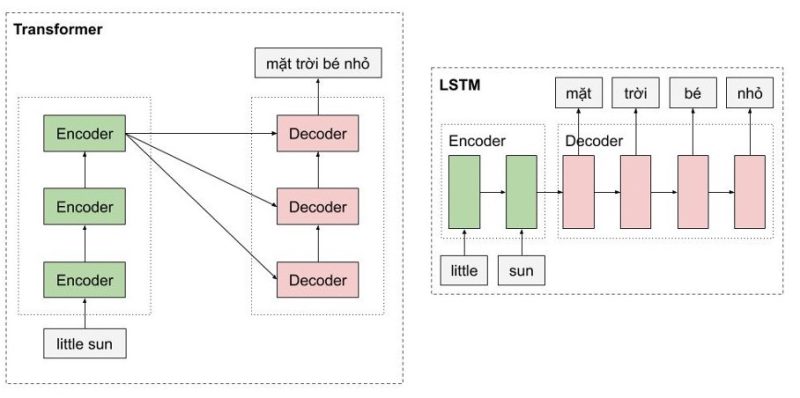
Hình 6: So sánh transformer và LSTM
Một cái nhìn vừa tổng quát và chi tiết sẽ giúp ích cho cho việc phân tích và đi tới sự lựa chọn cho model máy học hiệu quả. Một trong những phần quan trọng của encoder là sinusoidal position encoding, multi head attention.
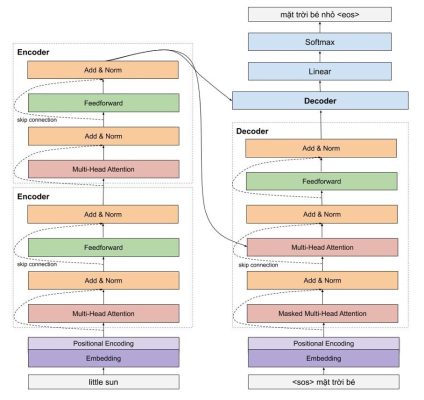
Hình 7: Mô hình tổng quan Encoder – Eecoder
Embedding layer with position encoding
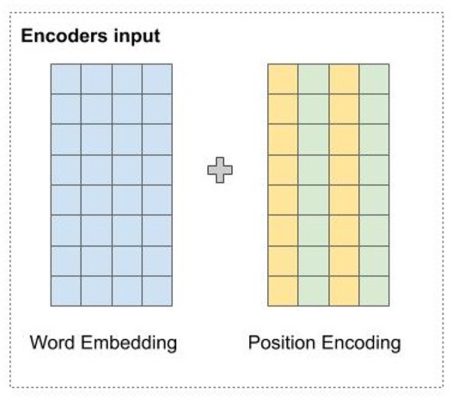
Trước khi đi vào mô hình encoder, chúng ta sẽ tìm hiểu cơ chế Position Encoding dùng để đưa thông tin về vị trí của các từ vào mô hình transformer.
Đầu tiên, các từ được biểu diễn bằng một vector sử dụng một ma trận word embedding có số dòng bằng kích thước của tập từ vựng. Sau đó các từ trong câu được tìm kiếm trong ma trận này, và được nối nhau thành các dòng của một ma trận 2 chiều chứa ngữ nghĩa của từng từ riêng biệt. Nhưng transformer xử lý các từ song song, do đó, với chỉ word embedding mô hình không thể nào biết được vị trí các từ.
Như vậy, chúng ta cần một cơ chế nào đó để đưa thông tin vị trí các từ vào trong vector đầu vào. Đó là lúc positional encoding xuất hiện và giải quyết vấn đề của chúng ta. Tuy nhiên, trước khi giới thiệu cơ chế position encoding, có thể giải quyết vấn đề băng một số cách naive như sau:
Biểu diễn vị trí các từ bằng chuỗi các số liên tục từ 0,1,2,3 …, n. Tuy nhiên, chúng ta gặp ngay vấn đề là khi chuỗi dài thì số này có thể khá lớn, và mô hình sẽ gặp khó khăn khi dự đoán những câu có chiều dài lớn hơn tất cả các câu có trong tập huấn luyện.
Để giải quyết vấn đề này, có thể chuẩn hóa lại cho chuỗi số này nằm trong đoạn từ 0-1 bằng cách chia cho n nhưng mà chúng ta sẽ gặp vấn đề khác là khoảng cách giữ 2 từ liên tiếp sẽ phụ thuộc vào chiều dài của chuỗi, và trong một khoản cố định, chúng ta không hình dùng được khoản đó chứa bao nhiêu từ. Điều này có nghĩa là ý nghĩa của position encoding sẽ khác nhau tùy thuộc vào độ dài của câu đó.
Sinusoidal position encoding
Vị trí của các từ được mã hóa bằng một vector có kích thước bằng word embedding và được cộng trực tiếp vào word embedding. Sinusoidal position encoding.
Cụ thể, tại vị trí chẵn, tác giả sử dụng hàm sin, và với vị trí lẽ tác giả sử dụng hàm cos để tính giá trị tại chiều đó.
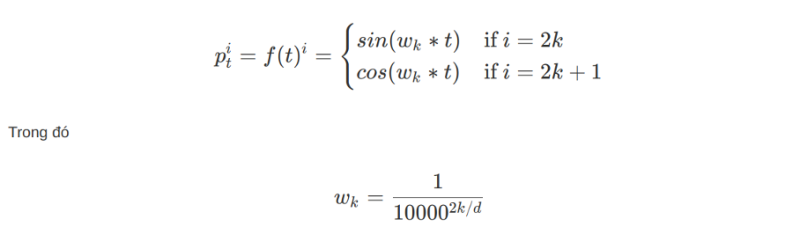
Trong hình dưới này, mình minh họa cho cách tính position encoding. Giả sử chúng ta có word embedding có 6 chiều, thì position encoding cũng có tương ứng là 6 chiều. Mỗi dòng tương ứng với một từ. Giá trị của các vector tại mỗi vị trí được tính toán theo công thức ở hình dưới.
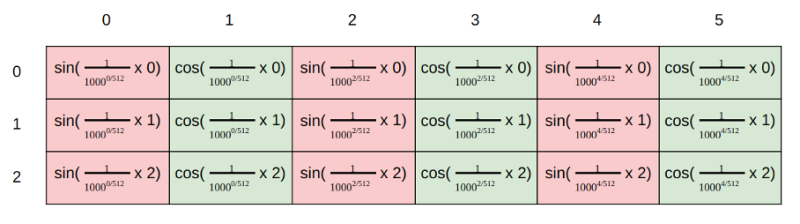
Hình 9: Cách tính position encoding
Lúc này chúng ta làm rõ tại sao lại có thể mã hóa thông tin vị trí của từ? Hãy tưởng tượng có các số từ 0 – 15. Chúng ta có thể thấy rằng bit ngoài cùng bên phải thay đổi nhanh nhất mỗi 1 số, và sau đó là bit bên phải thứ 2, thay đổi mỗi 2 số, tương tự cho các bit khác.

Hình 10: Sự thay đổi trên bit mã hóa thông tin
Trong công thức đề xuất, chúng ta cũng thấy rằng, hàm sin và cos có dạng đồ thị tần số và tần số này giảm dần ở các chiều lớn dần. Ở hình dưới, ở chiều 0, giá trị thay đổi liên tục tương ứng với màu sắc thay đổi liên tục, và tần số thay đổi này giảm dần ở các chiều lớn hơn.
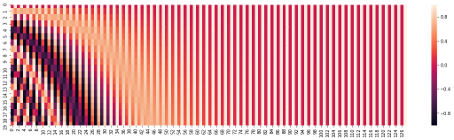
Hình 11: Đồ thị biểu diễn thay đổi tần số
Nên chúng ta có thể cảm nhận được việc biểu diễn khá tương tự như cách biểu diễn các số nguyên trong hệ nhị phân, cho nên chúng ta có thể biểu diễn được vị trí các từ theo cách như vậy.
Chúng ta cũng có thể xem ma trận khoảng cách của các vector biểu diễn vị trí như hình dưới. Rõ ràng, các vector biểu diễn thể hiện được tính chất khoảng cách giữ 2 từ. 2 từ cách càng xa nhau thì khoảng cách càng lớn hơn.
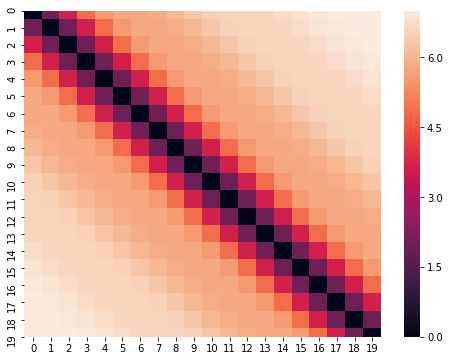
Hình 12: Ma trận vector thay đổi vị trí
Ngoài ra, một tính chất của phương pháp đề xuất là nó cho phép mô hình dễ dàng học được mối quan hệ tương đối giữ các từ. Cụ thể, biểu diễn vị trí của từ t + offset có thể chuyển thành biểu diễn vị trí của từ t bằng một phép biến đổi tuyến tính dựa trên ma trận phép quay.
Encoding
Encoder của mô hình transformer có thể bao gồm nhiều encoder layer tượng tự nhau. Mỗi encoder layer của transformer lại bao gồm 2 thành phần chính là multi head attention và feedforward network, ngoài ra còn có cả skip connection và normalization layer.
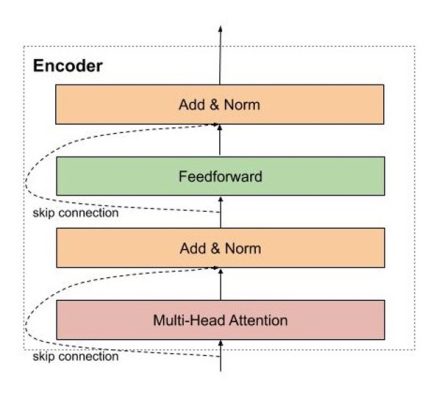
Hình 13: Mô tả các bước cơ bản encoder
Encoder đầu tiên sẽ nhận ma trận biểu diễn của các từ đã được cộng với thông tin vị trí thông qua positional encoding. Sau đó, ma trận này sẽ được xử lý bởi Multi Head Attention. Multi Head Attention thật chất là self-attention, nhưng mà để mô hình có thể có chú ý nhiều pattern khác nhau, đơn giản là sử dụng nhiều self-attention.
Self attention layer
Self attention cho phép mô hình khi mã hóa một từ có thể sử dụng thông tin của những từ liên quan tới nó. Ví dụ khi từ nó được mã hóa, nó sẽ chú ý vào các từ liên quan như là mặt trời. Cơ chế self attention này có ý nghĩa tương tự như cơ chế attention mình đã chia sẻ ở bài trước và những công thức toán học cũng tương ứng với nhau.
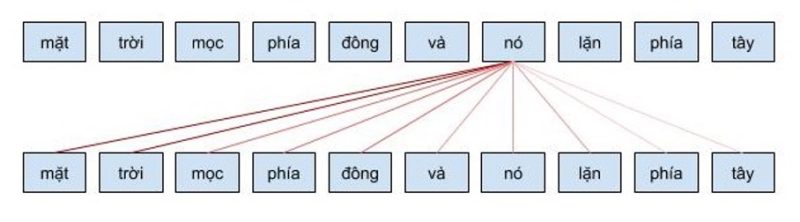
Hình 14: Cơ chế self attention
Có thể tưởng tượng cơ chế self attention giống như cơ chế tìm kiếm. Với một từ cho trước, cơ chế này sẽ cho phép mô hình tìm kiếm trong cách từ còn lại, từ nào “giống” để sau đó thông tin sẽ được mã hóa dựa trên tất cả các từ trên.
- query vector: vector dùng để chứa thông tin của từ được tìm kiếm, so sách. Giống như là câu query của google search.
- key vector: vector dùng để biểu diễn thông tin các từ được so sánh với từ cần tìm kiếm ở trên. Ví dụ, như các trang webs mà google sẽ so sánh với từ khóa mà chúng ta tìm kiếm.
-
value vector: vector biểu diễn nội dung, ý nghĩa của các từ. Chúng ta có thể tượng tượng, nó như là nội dung trang web được hiển thị cho người dùng sau khi tìm kiếm.
Để tính tương quan, chúng ta đơn giản chỉ cần tính tích vô hướng dựa các vector query và key. Sau đó dùng hàm softmax để chuẩn hóa chỉ số tương quan trong đoạn 0-1, và cuối cùng, tính trung bình cộng có trọng số giữa các vector values sử dụng chỉ số tương quan mới tính được.
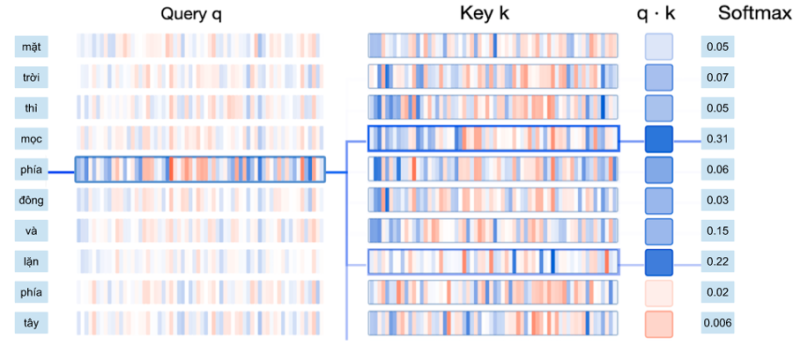
Hình 15: Tính trọng số các vector
Cụ thể hơn, quá trình tính toán attention vector có thể được tóm tắt làm 3 bước như sau:
- Bước 1: Tính ma trận query, key, value bằng cách khởi tạo 3 ma trận trọng số query, key, vector. Sau đó nhân input với các ma trận trọng số này để tạo thành 3 ma trận tương ứng.
- Bước 2: Tính attention weights. Nhân 2 ma trận key, query vừa được tính ở trên với nhau để với ý nghĩa là so sánh giữ câu query và key để học mối tương quan. Sau đó thì chuẩn hóa về đoạn [0-1] bằng hàm softmax. 1 có nghĩa là câu query giống với key, 0 có nghĩa là không giống.
- Bước 3: Tính output. Nhân attention weights với ma trận value. Điều này có nghĩa là chúng ta biểu diễn một từ bằng trung bình có trọng số (attention weights) của ma trận value.
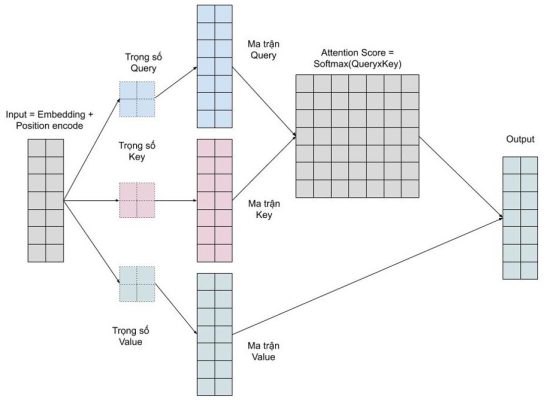
Hình 16: Chi tiết cách thực hiện tính trọng số vector
Multi head attention
Chúng ta muốn mô hình có thể học nhiều kiểu mối quan hệ giữ các từ với nhau. Với mỗi self-attention, chúng ta học được một kiểu pattern, do đó để có thể mở rộng khả năng này, chúng ta đơn giản là thêm nhiều self-attention. Tức là chúng ta cần nhiều ma trận query, key, value. Giờ đây ma trận trọng số key, query, value sẽ có thêm 1 chiều depth nữa.
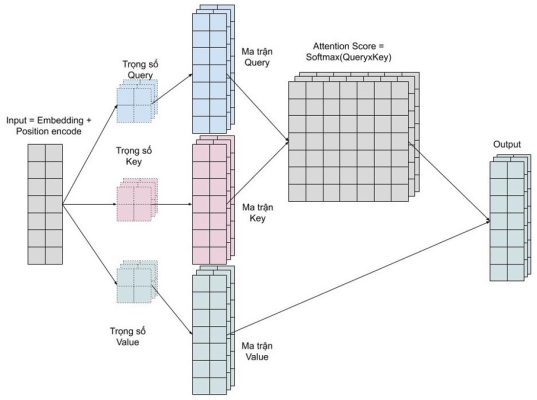
Hình 17: Ma trận biểu diễn trọng số
Multi head attention cho phép mô hình chú ý đến đồng thời những pattern dễ quan sát được như sau.
- Chú ý đến từ kế trước của một từ
- Chú ý đến từ kế sau của một từ
- Chú ý đến những từ liên quan của một từ
Decoder
Decoder thực hiện chức năng giải mã vector của câu nguồn thành câu đích, do đó decoder sẽ nhận thông tin từ encoder là 2 vector key và value. Kiến trúc của decoder rất giống với encoder, ngoại trừ có thêm một multi head attention nằm ở giữ dùng để học mối liên quan giữ từ đang được dịch với các từ được ở câu nguồn.
Hình 18: Mô hình biểu diễn Decoder
Label smoothing
Với mô hình nhiều triệu tham số của transformer, thì việt overfit là chuyện dễ dàng xảy ra. Để hạn chế hiện tượng overfit, chúng ta có thể sử dụng kỹ thuật label smoothing. Về cơ bản thì ý tưởng của kỹ thuật này khá đơn giản, chúng ta sẽ phạt mô hình khi nó quá tự tin vào việc dự đoán của mình. Thay vì mã hóa nhãn là một one-hot vector, cần sẽ thay đổi nhãn này một chút bằng cách phân bố một tí xác suất vào các trường hợp còn lại.
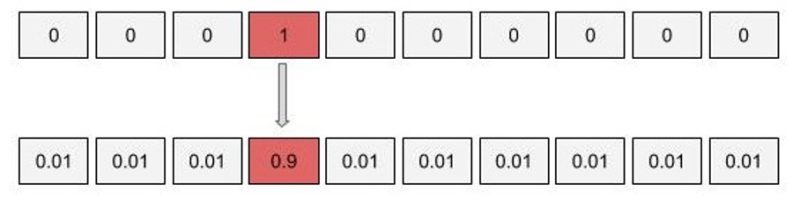
Hình 19: kĩ thuật hạn chế overfiting
Giờ có thể an tâm khi có thể để số epoch lớn mà không lo rằng mô hình sẽ overfit.
Thực nghiệm
Code tải tại đây
Thu thập dữ liệu
Bộ dữ liệu thực nghiệm:
| STT | Tên bộ dữ liệu | Số câu | Link download |
| 1 | train.en | 133317 | Link tải |
| 2 | train.vi | 133317 | |
| 3 | tst2013 | 1268 | |
| 4 | tst2013.vi | 1268 |
Xử lý dữ liệu
- Loại bỏ các ký tự đặc biệt như dấu sao (*), ngoặc kép (“), dấu ngoặc kép đôi (“”).
- Loại bỏ các dấu xuống dòng (newlines), dấu chấm, dấu cộng, dấu trừ, dấu gạch chéo, dấu bằng, ngoặc đơn, dấu hai chấm, dấu ngoặc vuông, dấu gạch đứng, dấu chấm than (!), dấu chấm phẩy (,), và dấu hỏi (?).
- Biến đổi câu thành chữ thường (viết thường).
Công nghệ sử dụng
Google Colab (viết tắt của Google Colaboratory) là một dịch vụ miễn phí dựa trên đám mây được cung cấp bởi Google, cho phép chạy và thực thi mã Python trong một môi trường dựa trên web.
Python là một ngôn ngữ lập trình bậc cao cho các mục đích lập trình đa năng, đặc biệt trong lĩnh vực học máy, học sâu và trí tuệ nhân tạo với bộ thư viện tiêu chuẩn lớn sử dụng cho hầu hết mọi tác vụ.
Bộ thư viện Python sử dụng trong bài toán: torch, numby, os, math, torchtext, nltk, re, spacy, dill, panda, seaborn, matplotlib …
Xây dựng mô hình và huấn luyện
- Xây dựng encoder – decoder nhiều layer
- Xây dựng transformer
- Tạo mark trong decoder để dự đoán trong quá trình huấn luyện mô hình các từ không có trong tương lai
- Tạo mark cho encoder để mô hình không bỏ các kí tự PAD được thêm vào.
- Tính toán loss tập validation
- Sử dụng Adam để tối ưu hóa, beam seach trong tìm kiếm, cải thiện trong dự đoán.
- Sử dụng label smoothing tránh overfiting
Đánh giá mô hình
Đánh giá mô hình dịch máy tiếng anh sang tiếng việt thông qua khả năng dịch máy, phương pháp tự động và tiêu chuẩn để đánh giá dịch thuật dựa trên sự so sánh giữa bản dịch máy và bản dịch tham chiếu do con người tạo ra.
Các bước cơ bản để tính BLUE:
- Dữ liệu Tham chiếu (Reference Data): Để tính BLEU Score, cần có ít nhất một bản dịch tham chiếu do con người tạo ra cho mỗi câu hoặc văn bản mục tiêu. Đây là bản dịch muốn mô hình dịch máy so sánh và đánh giá.
- Tỷ lệ N-Grams: BLEU Score sử dụng các N-grams (tỷ lệ từ hoặc cụm từ liên tiếp) để so sánh bản dịch máy và bản dịch tham chiếu. Thông thường, BLEU sử dụng từ unigram (1-gram) đến 4-gram cho các bản dịch ngôn ngữ tự nhiên.
- Đo lường Precision: Để đo lường BLEU Score, nó sẽ tính toán precision cho từng N-gram level, sau đó kết hợp chúng thành một điểm số tổng quan. Precision ở đây là tỷ lệ số lượng N-grams giống nhau giữa bản dịch máy và bản dịch tham chiếu so với tổng số N-grams trong bản dịch máy.
- Tính trọng số cho N-grams: BLEU Score có thể tính trọng số khác nhau cho các N-grams dựa trên khoảng cách N-grams và độ dài của câu. Điều này giúp đánh giá chất lượng dịch thuật một cách cân bằng.
- Kết hợp Precision: Precision cho mỗi level N-gram sẽ được kết hợp để tạo thành một điểm số tổng quan, và điểm số này thường nằm trong khoảng từ 0 đến 1.
- Kết quả BLEU Score: BLEU Score càng gần 1, thì bản dịch máy càng giống với bản dịch tham chiếu, và chất lượng dịch thuật càng cao.
Kết Quả & Đánh Giá
| Số epochs | Thuật toán | Thời gian thực hiện | BLUE |
| 20 | Transformer | 240.73 phút | 0.2547 |
Nhận xét và đánh giá:
Mặc dù thực hiện qua 20 epochs một số lượng còn tương đối ít so với nhiều mô hình dịch máy hiện đại. Tùy thuộc vào tài nguyên và kích thước của tập dữ liệu, việc tăng số epochs có thể cải thiện kết quả. Thuật toán Transformer là một lựa chọn tốt, đặc biệt là cho các nhiệm vụ xử lý ngôn ngữ tự nhiên. Điều này cho thấy rằng mô hình đã sử dụng một kiến trúc mạng nổi tiếng và phù hợp.
Thời gian huấn luyện (240,73 phút) có vẻ khá hợp lý, tuy nhiên, đây có thể là một yếu tố phụ thuộc vào tài nguyên máy tính và kích thước của tập dữ liệu. Giá trị BLEU Score 0.2547 chỉ ra rằng mô hình dịch máy có khả năng dịch, nhưng chất lượng dịch có thể chưa cao. Có một số cụm từ hoặc cấu trúc ngữ pháp chưa được dịch tốt. Điều này có thể là một kết quả của việc huấn luyện trong một số epochs có giới hạn.
Kết Luận
Bài viết này tập trung vào việc xây dựng mô hình dịch máy sử dụng mạng nơ-ron sâu với kiến trúc Transformer – một kiến trúc tiên tiến trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP). Mô hình này đã được huấn luyện trên một tập dữ liệu lớn, cho phép nó hiểu và xử lý ngôn ngữ tự nhiên một cách hiệu quả hơn. Qua quá trình huấn luyện, kết quả đạt được là rất khả quan, mở ra tiềm năng lớn cho các ứng dụng dịch máy tự động trong thực tế.
Để đo lường chất lượng của mô hình, chúng tôi đã sử dụng BLEU Score, một thước đo phổ biến trong việc đánh giá độ chính xác của các mô hình dịch máy. Kết quả cho thấy mô hình của chúng tôi đã đạt được BLEU Score cao hơn so với các mô hình cơ bản trước đó, chứng minh tính hiệu quả và tiềm năng của việc áp dụng kiến trúc Transformer.
Bằng cách áp dụng kiến trúc Transformer, mô hình dịch máy của chúng tôi không chỉ cải thiện về độ chính xác mà còn cho thấy tiềm năng ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau. Hy vọng rằng bài viết này sẽ giúp bạn có cái nhìn rõ ràng hơn về cách xây dựng và đánh giá mô hình dịch máy sử dụng mạng nơ-ron sâu, đồng thời khẳng định vai trò quan trọng của kiến trúc Transformer trong xử lý ngôn ngữ tự nhiên hiện đại.