









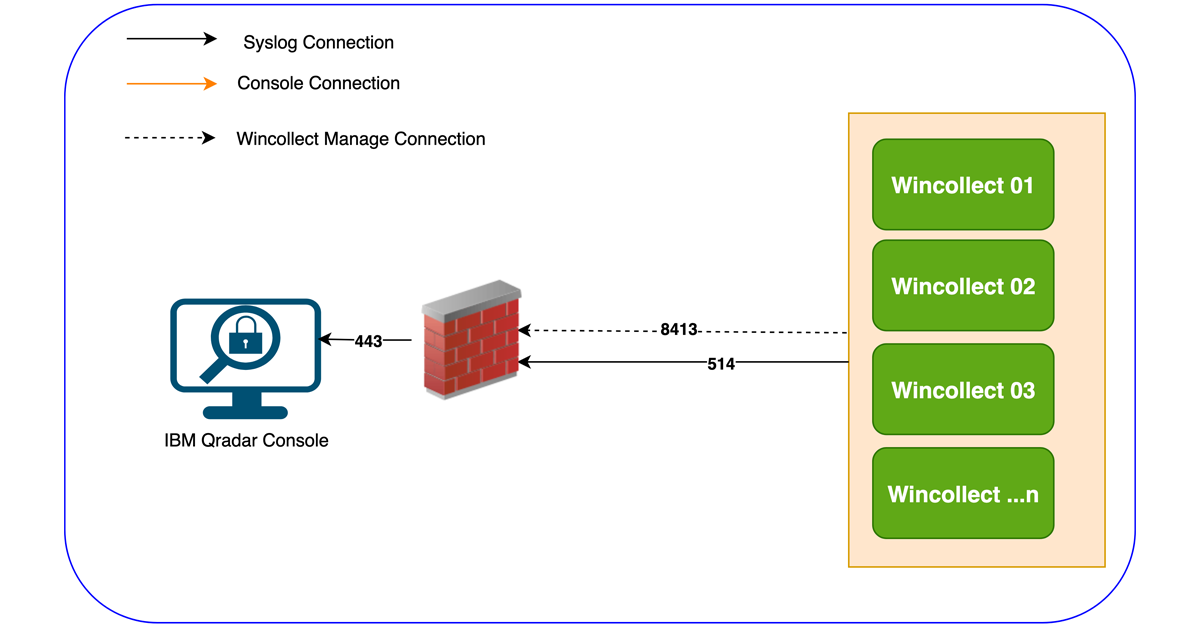


![Series [CA]: Phần 2 Create SAN Certificate](https://phuongit.com/wp-content/uploads/2024/10/San-Cert.png)
Giới Thiệu Mạng Học Sâu Unet
Mạng học sâu UNet là một mô hình deep learning được sử dụng rộng rãi trong việc phân đoạn ảnh, đặc biệt là trong việc phân đoạn các đối tượng trong các bức ảnh medical. Nguyên lý hoạt động của UNet là sử dụng một mô hình encoder-decoder, trong đó mô hình encoder được sử dụng để học các đặc trưng của bức ảnh đầu vào và mô hình decoder được sử dụng để dự báo các nhãn cho các vùng trong bức ảnh. Mô hình UNet còn bao gồm một số thành phần đặc trưng khác, bao gồm các skip connections giúp nối các tầng encoder với các tầng decoder, giúp cho mô hình có khả năng tối ưu hơn trong việc học các đặc trưng của bức ảnh.
Trong bài viết này, chúng ta sẽ tìm hiểu về cách ứng dụng mô hình học sâu U-Net để thực hiện nhiệm vụ phân đoạn ảnh X-quang phổi. Chúng ta không chỉ phân tích cơ chế hoạt động của U-Net mà còn đánh giá hiệu suất của mô hình khi áp dụng trên các tập dữ liệu thực tế. Điều này mở ra những tiềm năng lớn trong việc ứng dụng công nghệ học sâu vào lĩnh vực y tế, hướng đến mục tiêu cải thiện chất lượng chẩn đoán và giảm tải cho các chuyên gia y khoa.
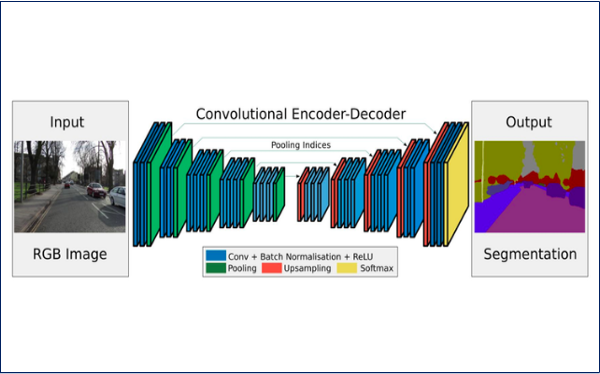
Hình 1: Nguyên lý hoạt động mạng học sâu Unet
Giải thích nguyên lý hoạt động:
Trong quá trình encoder của mô hình UNet, mô hình sử dụng một mạng neural để học các đặc trưng của bức ảnh đầu vào. Điều này được thực hiện bằng cách sử dụng các tầng convolutional và pooling để tìm các đặc trưng có ý nghĩa trong bức ảnh và giảm kích thước của bức ảnh. Khi bức ảnh đi qua quá trình encoder, nó sẽ được giảm kích thước và các đặc trưng sẽ được học tốt hơn. Quá trình này giúp cho mô hình có thể học được các đặc trưng của bức ảnh đầu vào mà không bị mất thông tin quan trọng.
Sau khi bức ảnh đi qua quá trình encoder, nó sẽ được truyền vào quá trình decoder của mô hình UNet. Trong quá trình decoder, mô hình sử dụng các tầng convolutional và upsampling để phục hồi lại kích thước của bức ảnh và dự báo các nhãn cho các vùng trong bức ảnh. Mô hình sử dụng các skip connections để nối các tầng encoder với các tầng decoder, giúp cho mô hình có thể sử dụng các đặc trưng đã được học trong quá trình encoder để đưa ra các dự đoán chính xác hơn. Khi bức ảnh đi qua quá trình decoder, nó sẽ được phục hồi lại kích thước ban đầu và được gán các nhãn cho các vùng trong bức ảnh.
Trong mô hình UNet, các skip connections được sử dụng để nối các tầng encoder với các tầng decoder. Mỗi tầng encoder sẽ được nối với một tầng decoder tương ứng và các tầng này sẽ chia sẻ các đặc trưng học được. khi bức ảnh đi qua quá trình encoder, các tầng sẽ học các đặc trưng của bức ảnh và giảm kích thước của bức ảnh. Khi bức ảnh đi qua quá trình decoder, các tầng sẽ phục hồi lại kích thước của bức ảnh và dự báo các nhãn cho các vùng trong bức ảnh. Trong quá trình này, các tầng decoder sẽ sử dụng các skip connections để nối với các tầng encoder tương ứng và sử dụng các đặc trưng đã được học trong quá trình encoder để đưa ra các dự đoán chính xác hơn. Các skip connections giúp cho mô hình UNet có khả năng tối ưu hơn trong việc học các đặc trưng của bức ảnh và giúp cho mô hình có khả năng phục hồi lại các chi tiết của bức ảnh tốt hơn.
Kiến Trúc Mạng Học Sâu Unet
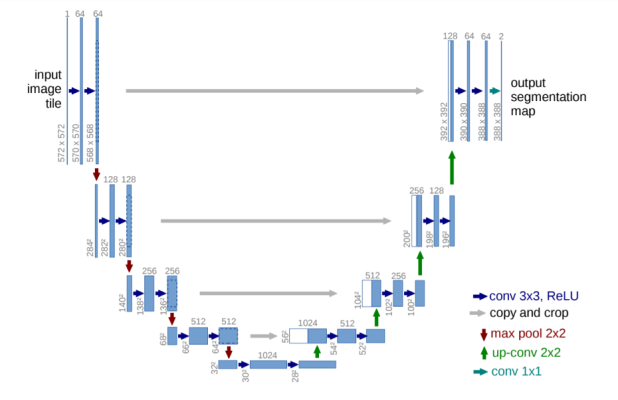
Hình 2: Kiến trúc mạng học sâu Unet
Mỗi một thanh chữ nhật màu xanh là một feature map đa kênh. Kích thước width x height được kí hiệu góc trái bên dưới của thanh chữ nhật và số lượng channels được kí hiệu trên đỉnh của feature map. Các thanh chữ nhật màu trắng bên nhánh phải của hình chữ U được copy từ nhánh bên trái và concatenate vào nhánh bên phải. Mỗi một mũi tên có màu sắc khác nhau tương ứng với một phép biến đổi khác nhau như chúng ta có thể thấy trong mô tả của mạng.
Mạng Unet bao gồm 2 nhánh đối xứng nhau hình chữ U nên được gọi là Unet.
Kiến trúc mạng Unet bao gồm 2 phần là phần thu hẹp (contraction) ở bên trái và phần mở rộng (expansion) ở bên phải. Mỗi phần sẽ thực hiện một nhiệm vụ riêng như sau:
Phần thu hẹp: Làm nhiệm vụ trích lọc đặc trưng để tìm ra bối cảnh của hình ảnh. Vai trò của phần thu hẹp tương tự như một Encoder. Một mạng Deep CNN sẽ đóng vai trò trích lọc đặc trưng. Lý do nhánh được gọi là thu hẹp vì kích thước dài và rộng của các layers giảm dần. Từ input kích thước 572×572 chỉ còn 32×32. Đồng thời độ sâu cũng tăng dần từ 3 lên 512.
Phần mở rộng: Gồm các layer đối xứng tương ứng với các layer của nhánh thu hẹp. Quá trình Upsampling được áp dụng giúp cho kích thước layer tăng dần lên. Sau cùng ta thu được một ảnh mask đánh dấu nhãn dự báo của từng pixel.
Giải Thuật Học Sâu Unet
Khởi tạo mô hình Unet
- Khởi tạo kích thước đầu vào của ảnh (input size) và số lượng lớp phân loại (num_classes).
- Xây dựng một mô hình CNN bằng cách sử dụng các lớp tích chập (convolutional layers), lớp pooling (pooling layers), lớp upsample (upsample layers), và các kết nối skip.
- Sử dụng hàm kích hoạt tùy chọn (ví dụ như ReLU) và hàm kích hoạt softmax hoặc sigmoid cho lớp đầu ra để phân loại từng pixel.
Huấn luyện mô hình Unet
- Tiền xử lý tập dữ liệu huấn luyện để chuẩn hóa giá trị pixel (ví dụ như chia tỷ lệ giá trị pixel về khoảng 0 đến 1).
- Sử dụng các chiến lược tăng cường dữ liệu (data augmentation) để mở rộng tập dữ liệu huấn luyện, ví dụ như xoay, phóng to hoặc thu nhỏ ảnh.
- Huấn luyện mô hình Unet trên tập dữ liệu huấn luyện bằng cách sử dụng các kỹ thuật tối ưu hóa như stochastic gradient descent (SGD) hoặc Adam.
- Đánh giá mô hình trên tập dữ liệu kiểm tra bằng cách tính toán độ chính xác (accuracy), độ đo F1, hay bất kỳ độ đo nào khác được sử dụng trong phân đoạn ảnh.
Sử dụng mô hình học sâu Unet để dự đoán
- Tiền xử lý ảnh đầu vào để chuẩn hóa giá trị pixel.
- Sử dụng mô hình Unet để dự đoán các lớp phân loại cho từng pixel trong ảnh.
- Áp dụng các kỹ thuật xử lý sau dự đoán, chẳng hạn như chuyển từ định dạng mask sang định dạng hình ảnh.
Minh Họa Học Sâu Unet
Để thực hiện phân đoạn ảnh với những bất thường trên hình ảnh X-quang phổi, ta sẽ sử dụng một mô hình Unet. Mô hình này được huấn luyện trên tập dữ liệu X-quang phổi có chứa các ảnh đã được gán nhãn (là ảnh gốc được đánh dấu các vùng khác – bất thường).
Quá trình phân đoạn ảnh bằng Unet bao gồm hai giai đoạn chính:
- Giai đoạn mã hóa (Encoder): Mô hình Unet sẽ thực hiện việc mã hóa thông tin từ ảnh đầu vào thông qua một chuỗi các lớp tích chập (Convolutional Layer) để tìm ra các đặc trưng của hình ảnh. Các đặc trưng này sẽ được lưu lại để sử dụng ở giai đoạn giải mã (Decoder).
- Giai đoạn giải mã (Decoder): Ở giai đoạn này, mô hình Unet sẽ thực hiện việc giải mã các đặc trưng đã được mã hóa ở giai đoạn trước đó. Việc này được thực hiện bằng cách kết hợp các đặc trưng đã được lưu trữ với các lớp tích chập ngược (Deconvolutional Layer) để tái tạo lại hình ảnh ban đầu với kết quả phân đoạn.
Khi huấn luyện mô hình, ta sử dụng hàm mất mát dice loss để đo lường độ chính xác của kết quả phân đoạn so với nhãn. Sau khi mô hình đã được huấn luyện, ta sử dụng nó để phân đoạn các ảnh X-quang phổi mới, kết quả sẽ cho ta các vùng ảnh có sự khác biệt và bình thường trên hình ảnh X-quang phổi.
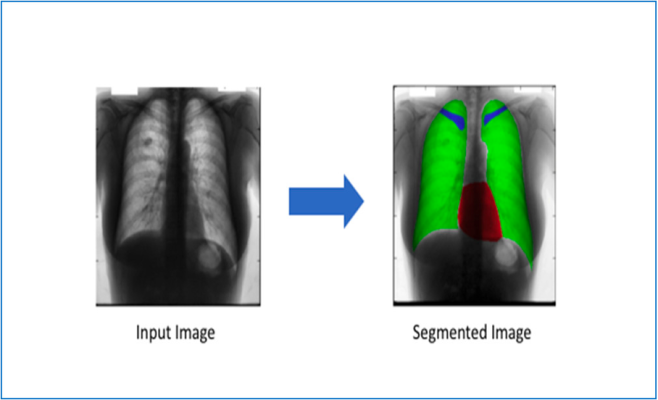
Hình 3: Kết quả trước và sau khi phân đoạn ảnh X-Quang
Thực Nghiệm
Thuộc tính dữ liệu
| STT | Tên thuộc tính | Loại thuộc tính | Số lượng | Ý nghĩa thuộc tính |
| 1 | Hình ảnh | png | 566 | Mặt nạ phổi phân đoạn thủ công |
| 2 | Hình ảnh | png | 843 | Dữ liệu X-Quang phổi bất thường |
| 3 | Hình ảnh | png | 1365 | Dữ liệu CXR X-Quang |
| 4 | Hình ảnh | png | 843 | MCU CXR Mask phải |
| 5 | Hình ảnh | png | 844 | MCU CXR Mask trái |
Bảng 1: Bảng thuộc tính dữ liệu
| STT | Tên dữ liệu | Nguồn dữ liệu |
| 1 | Phân đoạn ảnh trong phổi | https://www.kaggle.com/datasets/yoctoman/shcxr-lung-mask
https://www.kaggle.com/datasets/kmader/pulmonary-chest-xray-abnormalities |
Bảng 2: Tập dữ liệu thực nghiệm
Phương pháp đánh giá độ đo
Các độ đo MSE, DICE và IOU cũng có thể được sử dụng để đánh giá độ chính xác của phương pháp phân đoạn ảnh.
- MSE (Mean Squared Error): Đây là một độ đo để đánh giá sự khác biệt giữa giá trị dự đoán và giá trị thực tế trong các bài toán regression. Trong bài toán phân đoạn ảnh, MSE có thể được tính bằng cách lấy trung bình bình phương của sự khác biệt giữa giá trị pixel dự đoán và giá trị pixel thực tế trên toàn bộ ảnh. Tuy nhiên, MSE thường không được sử dụng nhiều trong bài toán phân đoạn ảnh vì nó không quan tâm đến cấu trúc và hình dáng của đối tượng cần phân đoạn.
- DICE (Dice coefficient): Đây là một độ đo thường được sử dụng trong bài toán phân đoạn ảnh. Dice coefficient tính toán tỷ lệ giữa diện tích giao của phân đoạn dự đoán và phân đoạn thực tế so với diện tích tổng của phân đoạn dự đoán và phân đoạn thực tế. Độ đo này càng gần 1 thì phân đoạn càng chính xác.
- IOU (Intersection over Union): Đây cũng là một độ đo tương tự Dice coefficient và được sử dụng trong bài toán phân đoạn ảnh. IOU tính toán tỷ lệ giữa diện tích giao của phân đoạn dự đoán và phân đoạn thực tế so với diện tích hợp của phân đoạn dự đoán và phân đoạn thực tế. Độ đo này cũng càng gần 1 thì phân đoạn càng chính xác.
Chạy thực nghiệm
Code tải tại đây
| Epoch | DICE | IOU | MSE |
| 1 | 0.3639 | 0.3071 | 0.3179 |
| 2 | 0.5099 | 0.3920 | 0.4933 |
| 3 | 0.7370 | 0.5936 | 0.8729 |
| … | … | … | … |
| 50 | 0.9479 | 0.9052 | 0.9741 |
Bảng 3: Kết quả các độ đo
- Đánh giá: Khi thực hiện chạy với số lượng Epochs càng cao thì độ chính xác càng lớn. Giá trị và phân đoạn ảnh phổi chỉ ra sự khác nhau chính xác các vị trí, vùng ảnh so với ảnh mask. Đây là một ý nghĩa to lớn trong việc phát hiện sớm, chuẩn đoán bệnh.
Kết Luận
Trong nghiên cứu này, mô hình U-Net đã chứng minh tính hiệu quả vượt trội trong việc phân đoạn ảnh X-quang phổi, một nhiệm vụ quan trọng trong chẩn đoán y tế, đặc biệt là các bệnh về đường hô hấp như viêm phổi hoặc COVID-19. Với kiến trúc đặc thù cho các bài toán phân đoạn hình ảnh, U-Net đã cung cấp độ chính xác cao và khả năng tái tạo hình ảnh chi tiết nhờ vào việc duy trì thông tin không gian trong quá trình truyền tín hiệu qua các lớp mạng.
Nghiên cứu này mở ra hướng đi tiềm năng trong việc ứng dụng học sâu, đặc biệt là U-Net, vào lĩnh vực y tế, góp phần hỗ trợ các chuyên gia chẩn đoán nhanh chóng và chính xác hơn. Trong tương lai, các nghiên cứu mở rộng có thể tập trung vào việc kết hợp mô hình U-Net với các mô hình học sâu khác, cải thiện hiệu suất và tính toàn vẹn trong các ứng dụng thực tế.
Hi vọng bài viết mang lại chút kiến thức cho các bạn đam mê trong lĩnh vực nghiên cứu thị giác máy tính và học sâu. Cùng theo dõi để có những bài viết tiếp theo mình chia sẻ nhé.