Tuy nhiên, trong những năm gần đây, một hình thức mới của thư điện tử đã xuất hiện với số lượng lớn gây phiền hà cho người nhận và thiệt hại không nhỏ cho nền kinh tế gọi là thư rác hay spam emails.Một bức thư được gọi là thư rác chỉ khi nó là thư không yêu cầu và được gửi hàng loạt. Hoặc là những bức thư làm quen, được gửi lần đầu tiên hay bức thư gửi cho khách hành của các công ty, các nhà cung cấp dịch vụ…
Như vậy, thư rác là thư không yêu cầu và được gửi hàng loạt. Nhưng yếu tố quan trọng nhất để phân biệt thư rác với thư thông thường phải là ở nội dung bức thư. Khi một người nhận được thư rác, người đó không thể xác định được thư có được gửi hàng loạt hay không nhưng có thể nói chính xác đó là thư rác sau khi xem nội dung thư. Đặc điểm này chính là cơ sở để học máy thực hiện phân loại thư rác bằng cách phân tích nội dung thư.
Phân Loại Thư Rác
Việc phân loại thư rác rất quan trọng không chỉ trong lĩnh vực tạo những bộ lọc thư rác phù hợp cho hiệu quả cao mà còn giúp cho việc ban hành các bộ luật chống thư rác thích hợp. Có rất nhiều cách phân loại thư rác. Dưới đây là một số loại điển hình nhất.
Thư rác có thể được phân loại theo mục tiêu của người gửi thư rác. Nhiều người gửi thư rác gửi e-mail hàng loạt vì lý do quảng cáo như gửi quảng cáo thương mại hoặc mời tham gia vào các chiến dịch chính trị, hoặc nhằm mục đích lừa đảo hay phân phối phần mềm độc hại như virus hay trojan. Phần này trình bày các loại thư rác phổ biến và đưa ra số liệu thống kê, nếu có.
Theo Statista , trong năm 2018, 281,1 tỷ thư điện tử được gửi và nhận hàng ngày. Điều này bao gồm hàng tỷ thư quảng cáo được gửi bởi các nhà tiếp thị mỗi ngày. Trong khi nhiều người dùng e-mail tin rằng nội dung như sẽ nằm trong mục thư rác (Spam), hay thư tiếp thị nói chung là vô hại, hoặc chỉ là gây khó chịu cho người dùng. Tính đến quý 2 năm 2018, chỉ 85% thư điện tử tiếp thị nằm trong Hộp thư đến (Inbox) của người dùng và 7% đã bị bộ lọc thư rác bắt được. Tuy nhiên, mọi thứ đang được cải thiện vào năm 2018, tỷ lệ đặt thư rác thương mại đã giảm xuống còn 9%, giảm từ 14% vào năm 2017.
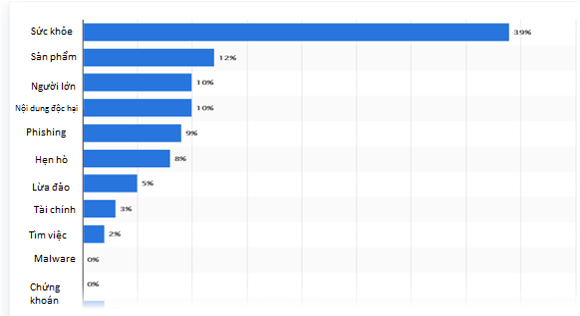
Hình 1: Thống kê phân loại các nội dung của thư rác năm 2020
Giới Thiệu Học Máy
Học máy được hiểu là một lĩnh vực con của Trí tuệ nhân tạo (Artificial Intelligence). Nó sử dụng những thuật toán cho phép máy tính có thể học từ dữ liệu để thực hiện các công việc thay vì được lập trình một cách rõ ràng.
Học máy là một ứng dụng của trí tuệ nhân tạo (AI) cung cấp cho các khả năng tự động học hỏi và cải thiện từ kinh nghiệm mà không cần lập trình rõ ràng. Học máy tập trung vào việc phát triển các chương trình máy tính có thể truy cập dữ liệu và sử dụng nó để tự học.
Các Thuật Toán Sử Dụng Trong Học Máy Có Giám Sát Lọc Thư Rác Phổ Biến
Máy vectơ hỗ trợ SVM là một khái niệm trong thống kê và khoa học máytính cho một tập hợp các phương pháp học có giám sát liên quan đến nhau để phân loại và phân tích hồi quy. SVM dạng chuẩn nhận dữ liệu vào và phân loại chúng vào hai lớp khác nhau. Do đó SVM là một thuật toán phân loại nhị phân. Với một bộ các ví dụ luyện tập thuộc hai thể loại cho trước, thuật toán luyện tập SVM xây dựng một mô hình SVM để phân loại các ví dụ khác vào hai thể loại đó.
Một mô hình SVM là một cách biểu diễn các điểm trong không gian và lựa chọn ranh giới giữa hai thể loại sao cho khoảng cách từ các ví dụ luyện tập tới ranh giới là xa nhất có thể. Các ví dụ mới cũng được biểu diễn trong cùng một không gian và được thuật toán dự đoán thuộc một trong hai thể loại tùy vào ví dụ đó nằm ở phía nào của ranh giới.
Các thử nghiệm thực tế cho thấy, phương pháp SVM có khả năng phân loại khá tốt đối với bài toán phân loại văn bản cũng như trong nhiều ứng dụng khác (như nhận dạng chữ viết tay, phát hiện mặt người trong các ảnh, ước lượng hồi quy,…). So sánh với các phương pháp phân loại khác, khả năng phân loại của SVM là tương đương hoặc tốt hơn đáng kể.
Bộ dữ liệu thực nghiệm sẽ bao gồm 02 thuộc tính chính. Chi tiết các thuộc tính được mô tả ở bảng dưới đây:
STT
Tên thuộc tính
Giá trị thuộc tính
Ý nghĩa thuộc tính
1
Label
Spam/Ham
Cho biết email thuộc loại là thư rác hay thư bình thường
2
Emailtext
Nội dung/thân của email
Cho biết nội dung của thư điện tử
Bảng 1: Tập Dữ Liệu Mẫu
Tập dữ liệu thực hiện trong thực nghiệm này là 5572 bản ghi, dưới đây là một vài dữ liệu mẫu:
Label
EmailText
ham
Go until jurong point, crazy.. Available only in bugis n great world la e buffet… Cine there got amore wat…
ham
Ok lar… Joking wif u oni…
spam
Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C’s apply 08452810075over18’s
ham
U dun say so early hor… U c already then say…
Bảng 2: Dữ liệu mẫu
Phương Pháp Đánh Giá
Ma Trận Nhầm Lẫn
Tính hiệu quả của giải thuật được đánh giá bởi chỉ số khôi phục (Recall), tỉ lệ chính xác (Precision), và hệ số điều hòa F-measure. Trong đó:
TP – True Positives: Tổng số email dự đoán đúng là email sạch
TN – True Negatives: Tổng số email đoán đúng là email spam
FP – False Positives: Tổng số email dự đoán là email sạch nhưng thực tế là email spam.
FN – False Negatives: Tổng số email dự đoán là email spam như thực tế là email sạch.
Tránh Overfitting
Trong nhiều trường hợp, chúng ta có rất hạn chế số lượng dữ liệu để xây dựng mô hình. Nếu lấy quá nhiều dữ liệu trong tập training ra làm dữ liệu validation, phần dữ liệu còn lại của tập training là không đủ để xây dựng mô hình. Lúc này, tập validation phải thật nhỏ để gee được lượng dữ liệu cho training đủ lớn. Tuy nhiên, một vấn đề khác nảy sinh. Khi tập validation quá nhỏ, hiện tượng overfitting lại có thể xảy ra với tập training còn lại. Cross validation sẽ giải quyết vấn đề này.
Cross validation là một cải tiến của validationvới lượng dữ liệu trong tập validation là nhỏ nhưng chất lượng mô hình được đánh giá trên nhiều tập validation khác nhau. Một cách thường đường sử dụng là chia tập training ra k tập con không có phần tử chung, có kích thước gần bằng nhau. Tại mỗi lần kiểm thử , được gọi là run, một trong số k tập con được lấy ra làm validate set. Mô hình sẽ được xây dựng dựa vào hợp của k−1 tập con còn lại. Mô hình cuối được xác định dựa trên trung bình của các train error và validation error. Cách làm này còn có tên gọi là k-fold cross validation.
Learning curve là một hàm trong python giúp phát hiện overfitting bằng cách so sánh training accuracy và cross-validation accuracy. Nếu training accuracy tăng cao trong khi cross-validation accuracy giảm dần hoặc không cải thiện nhiều, điều này có thể cho thấy mô hình đang overfitting dữ liệu. Trong trường hợp này, cần thử điều chỉnh các thông số của mô hình, sử dụng regularizations hoặc tăng số lượng dữ liệu để giảm overfitting.
Tuy nhiên, nếu training accuracy và cross-validation accuracy đều tăng một cách đồng đều, điều này cho thấy rằng mô hình đang học tốt và không có overfitting.
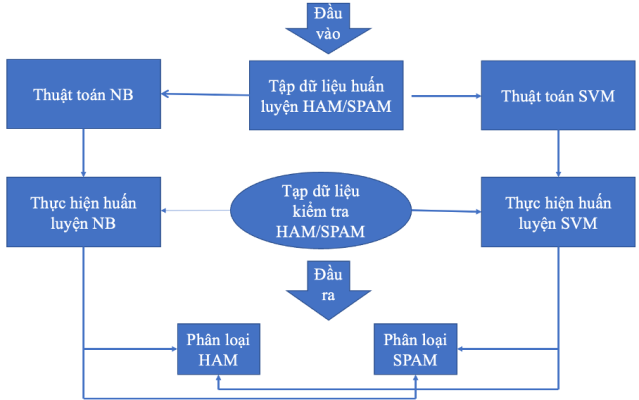
Mô Hình Học Máy & Thuật Toán
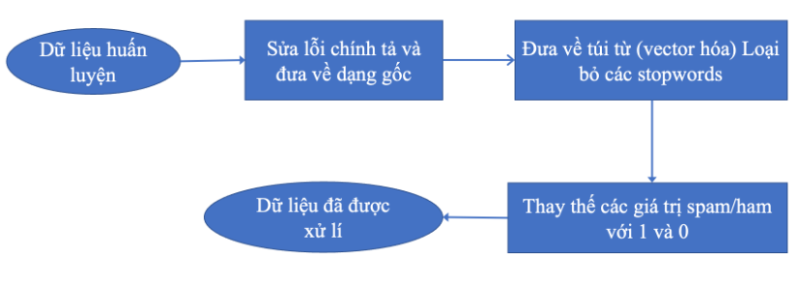
Giai đoạn 1: Thực hiện xử lí dự liệu đầu vào
Hình 5: Quá trình tiền xử lý dữ liệu
Sửa lỗi chính tả : Đầu vào là văn bản tinh. Sau bước xử lý này sẽ loại bỏ các lỗi chính tả do người dùng vô tình mắc phải nhằm tăng độ chính xác cho phần tiền xử lý. Thông thường phần dữ liệu đầu vào là chuẩn, do đó số lỗi chính tả gần như không có. Nên việc bỏ qua phần sửa lỗi không ảnh hưởng nhiều so với kết quả trong thực tế. Ví dụ: nếu thư chứa một số từ lỗi như “frei” có thể bị viết sai chính tả thành “free”. Stemmer sẽ ngăn chặn hoặc giảm từ lỗi đó thành từ gốc của nó, tức là “fre”. Do đó, “fre” là từ gốc của cả “free” và “frei”.
Đưa về túi từ, loại bỏ các stop words và thay thế các giá trị ham/spam bằng 0 và 1: Túi từ hoặc véc tơ hóa là quá trình chuyển đổi các từ trong câu thành định dạng véc tơ nhị phân. Nó rất hữu ích vì các mô hình yêu cầu dữ liệu ở định dạng số. Vì vậy, nếu từ có mặt trong câu cụ thể đó thì chúng ta sẽ đặt 1 nếu không thì 0. Điều này có thể đạt được bằng “TFidfVectorizer”. Ngoài ra, chúng tôi sẽ xóa những từ không bổ sung nhiều ý nghĩa cho câu của chúng tôi mà theo thuật ngữ kỹ thuật được gọi là “stop_words”. Ví dụ: những từ này có thể là nguyên âm, mạo từ hoặc một số từ thông dụng. Vì vậy, đối với điều này, chúng tôi sẽ thêm một tham số có tên là “stop_words” trong “TFidfVectorizer”.
Kết thúc giai đoạn 1, tập tin dữ liệu đã được xử lí và bắt đầu đưa vào thuật toán huấn luyện
Hình 6: Đưa dữ liệu vào xử lí với thuật toán học máy
Nhận xét: Thuật toán SVM cho kết quả chính xác hơn với các độ đo so với thuật toán NB, tuy nhiên thời gian chạy cho thuật toán SVM cao hơn nhiều lần so với NB
Thuật toán NB
Dự đoán (Ham)
Dự đoán (Spam)
Thực tế (Ham)
968
0
Thực tế (Spam)
45
102
Bảng 4: Kết quả ma trận confusion_matrix thuật toán NB
Thuật toán SVM
Dự đoán (Ham)
Dự đoán (Spam)
Thực tế (Ham)
966
2
Thực tế (Spam)
21
126
Bảng 5: Kết quả ma trận confusion_matrix thuật toán SVM
Nhận xét: Kết quả ma trận nhầm lẫn confusion_matrix cho thấy tỉ lệ phân loại email spam và email sạch giữa thực tế và dự đoán ở thuật toán SVM cao hơn so với NB.
Đánh Giá Kết Quả
Theo kết quả thực nghiệm cho thấy phương pháp Naïve Bayes cho kết quả kém hơn so với phương pháp SVM. Tuy nhiên, phương pháp Bayes có ưu thế rõ rệt về tốc độ phân loại do có độ phức tạp tính toán thấp hơn trong khi SVM đòi hỏi khối lượng và thời gian tính toán lớn hơn nhiều. Trong các thử nghiệm, tổng thời gian huấn luyện và phân loại bằng SVM lớn hơn Bayes nhiều lần.
Những phân tích của các tác giả trên đây và thực nghiệm cho thấy SVM có nhiều điểm phù hợp cho việc ứng dụng phân lớp thư điện tử. Và trên thực tế, các thí nghiệm phân lớp thư rác tiếng Anh chỉ ra rằng SVM đạt độ chính xác phân lớp cao và tỏ ra xuất sắc hơn so với các phương pháp phân lớp khác. Đó cũng chính là lý do tại sao SVM đang là lựa chọn cho các bài toán phân loại thư rác.
Hi vọng bài viết “Ứng Dụng Học Máy Trong Phân Loại Thư Rác” chia sẻ những kiến thức hữu ích để các bạn có cái nhìn về học máy trong phân loại thư rác cũng như các ứng dụng mà nó mang lại.












![Series [CA]: Phần 2 Create SAN Certificate](https://phuongit.com/wp-content/uploads/2024/10/San-Cert.png)