











![Series [CA]: Phần 2 Create SAN Certificate](https://phuongit.com/wp-content/uploads/2024/10/San-Cert.png)
Giới Thiệu Học Sâu Phát Hiện Đối Tượng
Trong thời đại kỹ thuật số, học sâu phát hiện đối tượng đã trở thành một công cụ đột phá trong lĩnh vực trí tuệ nhân tạo. Phương pháp này không chỉ giúp máy tính nhìn thấy mà còn hiểu rõ những gì chúng đang nhìn thấy trong hình ảnh hoặc video. Từ việc nhận diện khuôn mặt, phân tích cảnh quay đến hệ thống lái tự động, học sâu đã cách mạng hóa khả năng xử lý và phân tích dữ liệu thị giác.
Sự kết hợp giữa các mô hình mạng nơ-ron sâu (Deep Neural Networks) và các thuật toán học sâu cho phép hệ thống tự động phát hiện và phân loại hàng loạt đối tượng phức tạp trong thời gian thực với độ chính xác ấn tượng. Cơ hội ứng dụng của học sâu phát hiện đối tượng không chỉ dừng lại ở nhận diện hình ảnh, mà còn mở ra tiềm năng trong các lĩnh vực như y học, an ninh, và công nghiệp tự động hóa.
Thuật Toán Phát Hiện Hình Ảnh
Thuật Toán RCNN
Giới Thiệu Thuật Toán
R-CNN được giới thiệu lần đầu vào 2014 bởi Ross Girshick và các cộng sự ở UC Berkeley một trong những trung tâm nghiên cứu AI hàng đầu thế giới trong bài báo Rich feature hierarchies for accurate object detection and semantic segmentation.
Nó có thể là một trong những ứng dụng nền móng đầu tiên của mạng nơ ron tích chập đối với vấn đề định vị, phát hiện và phân đoạn đối tượng. Cách tiếp cận đã được chứng minh trên các bộ dữ liệu điểm chuẩn, đạt được kết quả tốt nhất trên bộ dữ liệu VOC-2012 và bộ dữ liệu phát hiện đối tượng ILSVRC-2013 gồm 200 lớp.
Mô Tả Thuật Toán
Kiến trúc của R-CNN gồm 3 thành phần đó là:
- Vùng đề xuất hình ảnh (Region proposal): Có tác dụng tạo và trích xuất các vùng đề xuất chứa vật thể được bao bởi các bounding box.
- Trích lọc đặc trưng (Feature Extractor): Trích xuất các đặc trưng giúp nhận diện hình ảnh từ các region proposal thông qua các mạng deep convolutional neural network.
- Phân loại (classifier): Dựa vào input là các features ở phần trước để phân loại hình ảnh chứa trong region proposal về đúng nhãn.
Kiến trúc của mô hình được mô tả trong biểu đồ bên dưới:
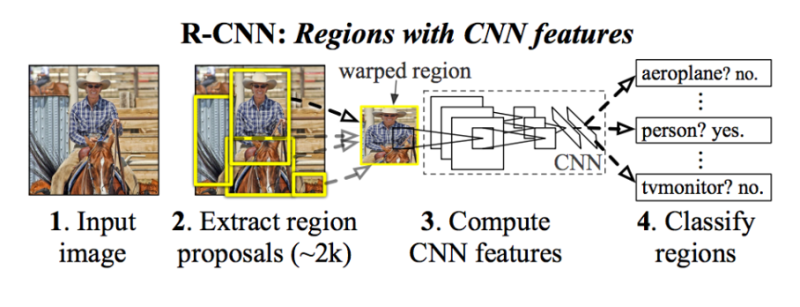
Hình 1 : Sơ đồ pipeline xử lý trong mô hình mạng R-CNN
Ta có thể nhận thấy các hình ảnh con được trích xuất tại bước 2 với số lượng rất lớn (khoảng 2000 region proposals). Tiếp theo đó áp dụng một mạng deep CNN để tính toán các feature tại bước 3 và trả ra kết quả dự báo nhãn ở bước 4 như một tác vụ image classification thông thường.
Thuật Toán Fast RCNN (2015)
Dựa trên thành công của R-CNN, Ross Girshick (lúc này đã chuyển sang Microsoft Research) đề xuất một mở rộng để giải quyết vấn đề của R-CNN trong một bài báo vào năm 2015 với tiêu đề rất ngắn gọn Fast R-CNN.
Bài báo chỉ ra những hạn chế của R-CNN đó là:
- Training qua một pipeline gồm nhiều bước: Pipeline liên quan đến việc chuẩn bị và vận hành ba mô hình riêng biệt.
- Chi phí training tốn kém về số lượng bounding box và thời gian huấn luyện: Mô hình huấn luyện một mạng CNN học sâu trên rất nhiều region proposal cho mỗi hình ảnh nên rất chậm.
- Phát hiện đối tượng chậm: Tốc độ xử lý không thể đảm bảo realtime.
Điểm đột phá của Fast R-CNN là sử dụng một single model thay vì pipeline để phát hiện region và classification cùng lúc.
Kiến trúc của mô hình trích xuất từ bức ảnh một tập hợp các region proposals làm đầu vào được truyền qua mạng deep CNN. Một pretrained-CNN, chẳng hạn VGG-16, được sử dụng để trích lọc features. Phần cuối của deep-CNN là một custom layer được gọi là layer vùng quan tâm (Region of Interest Pooling – RoI Pooling) có tác dụng trích xuất các features cho một vùng ảnh input nhất định.
Sau đó các features được kết bởi một lớp fully connected. Cuối cùng mô hình chia thành hai đầu ra, một đầu ra cho dự đoán nhãn thông qua một softmax layer và một đầu ra khác dự đoán bounding box (kí hiệu là bbox) dựa trên hồi qui tuyến tính. Quá trình này sau đó được lặp lại nhiều lần cho mỗi vùng RoI trong một hình ảnh.
Kiến trúc của mô hình được tóm tắt trong hình dưới đây:
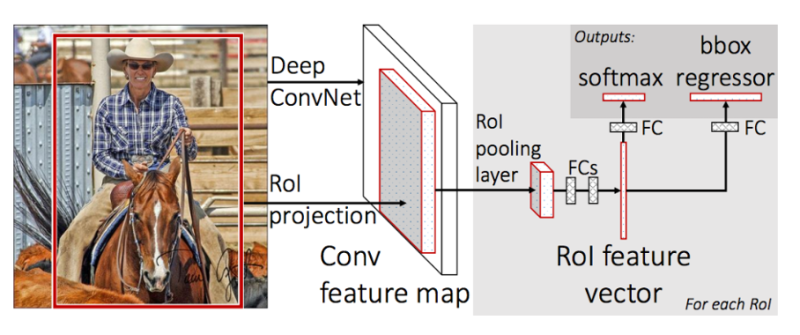
Hình 2 : Kiến trúc single model Fast R-CNN
Ở bước đầu ta áp dụng một mạng Deep CNN để trích xuất ra feature map. Thay vì warp image của region proposal như ở R-CNN chúng ta xác dịnh ngay vị trí hình chiếu của của region proposal trên feature map thông qua phép chiếu RoI projection. Vị trí này sẽ tương đối với vị trí trên ảnh gốc. Sau đó tiếp tục truyền output qua các layer RoI pooling layer và các Fully Connected layers để thu được RoI feature véc tơ. Sau đó kết quả đầu ra sẽ được chia làm 2 nhánh. 1 Nhánh giúp xác định phân phối xác suất theo các class của 1 vùng quan tâm Rồi thông qua hàm softmax và nhánh còn xác định tọa độ của bounding box thông qua hồi qui các offsets.
Thuật Toán Fast RCNN (2016)
Kiến trúc mô hình đã được cải thiện hơn nữa về cả tốc độ huấn luyện và phát hiện được đề xuất bởi Shaoqing Ren và các cộng sự tại Microsoft Research trong bài báo năm 2016 có tiêu đề Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Dịch nghĩa là “Faster R-CNN: Hướng tới phát hiện đối tượng theo thời gian thực với các mạng đề xuất khu vực”.
Kiến trúc được thiết kế để đề xuất và tinh chỉnh các region proposals như là một phần của quá trình huấn luyện, được gọi là mạng đề xuất khu vực (Region Proposal Network), hoặc RPN. Các vùng này sau đó được sử dụng cùng với mô hình Fast R-CNN trong một thiết kế mô hình duy nhất. Những cải tiến này vừa làm giảm số lượng region proposal vừa tăng tốc hoạt động trong thời gian thử nghiệm mô hình lên gần thời gian thực với hiệu suất tốt nhất. Tốc độ là 5fps trên một GPU.
Mặc dù là một mô hình đơn lẻ duy nhất, kiến trúc này là kết hợp của hai modules:
- Mạng đề xuất khu vực (Region Proposal Network, viết tắT là RPN). Mạng CNN để đề xuất các vùng và loại đối tượng cần xem xét trong vùng.
- Fast R-CNN: Mạng CNN để trích xuất các features từ các region proposal và trả ra các bounding box và nhãn.
Cả hai modules hoạt động trên cùng một output của một mạng deep CNN. Mạng RPN hoạt động như một cơ chế attention cho mạng Fast R-CNN, thông báo cho mạng thứ hai về nơi cần xem hoặc chú ý.
Kiến trúc của mô hình được tổng kết thông qua sơ đồ bên dưới:
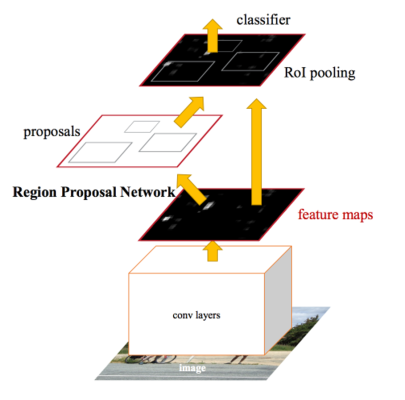
Hình 3 : Kiến trúc mô hình Faster R-CNN
Ở giai đoạn sớm sử dụng một mạng deep CNN để tạo ra một feature map. Khác với Fast R-CNN, kiến trúc này không tạo RoI ngay trên feature map mà sử dụng feature map làm đầu vào để xác định các region proposal thông qua một RPN network. Đồng thời feature maps cũng là đầu vào cho classifier nhằm phân loại các vật thể của region proposal xác định được từ RPN network.
RPN hoạt động bằng cách lấy đầu ra của một mạng pretrained deep CNN, chẳng hạn như VGG-16, và truyền feature map vào một mạng nhỏ và đưa ra nhiều region proposals và nhãn dự đoán cho chúng. Region proposals là các bounding boxes, dựa trên các anchor boxes hoặc hình dạng được xác định trước được thiết kế để tăng tốc và cải thiện khả năng đề xuất vùng. Dự đoán của nhãn được thể hiện dưới dạng nhị phân cho biết region proposal có xuất hiện vật thể hoặc không.
Thuật Toán YOLO
Giới Thiệu Thuật Toán
YOLO là viết tắt của “You Only Look Once,” và nó là một thuật toán phát hiện và nhận dạng đối tượng trong ảnh và video. YOLO là một trong những thuật toán quan trọng trong lĩnh vực thị giác máy tính và thị giác máy tính sâu (deep learning). Nó được giới thiệu bởi Joseph Redmon, Santosh Divvala, Ross Girshick và Ali Farhadi trong bài báo năm 2016 có tên “You Only Look Once: Unified, Real-Time Object Detection.”Đặc điểm chính của thuật toán YOLO bao gồm:
– Thời gian thực: YOLO được thiết kế để hoạt động ở tốc độ thời gian thực, có khả năng phát hiện và nhận dạng đối tượng trong thời gian rất ngắn trên các hình ảnh hoặc video.
– Chỉ nhìn một lần: YOLO tiến hành phát hiện và phân loại đối tượng trong một khung hình duy nhất một cách đồng thời, thay vì phải sử dụng nhiều bước xử lý như trong một số phương pháp trước đây. Điều này giúp YOLO nhanh hơn và đơn giản hóa quá trình.
– Mạng neural network sâu: YOLO sử dụng một mạng neural network sâu để trích xuất đặc trưng từ hình ảnh và dự đoán các bounding box (hộp giới hạn) xung quanh các đối tượng cùng với xác suất phân loại.
– Multiple Bounding Boxes: YOLO tạo ra nhiều bounding box cho mỗi vùng đối tượng, và sau đó sử dụng một thuật toán gọi là Non-Maximum Suppression để loại bỏ các bounding box trùng lặp và chọn ra bounding box cuối cùng cho mỗi đối tượng.
– Phù hợp với nhiều loại đối tượng: YOLO có khả năng nhận diện nhiều loại đối tượng khác nhau trong cùng một ảnh hoặc video, bao gồm cả đối tượng nhỏ và đối tượng lớn.
YOLO đã có nhiều phiên bản và cải tiến sau đó, bao gồm YOLOv2, YOLOv3, YOLOv4 và nhiều phiên bản khác, cung cấp hiệu suất tốt hơn và khả năng nhận diện đa dạng đối tượng. Thuật toán này được sử dụng rộng rãi trong các ứng dụng thị giác máy tính như giám sát an ninh, xe tự lái, xử lý ảnh y tế và nhiều lĩnh vực khác.
Mô Tả Thuật Toán
Phương pháp chính dựa trên một mạng neural network duy nhất được huấn luyện dạng end-to-end model. Mô hình lấy input là một bức ảnh và dự đoán các bounding box và nhãn lớp cho mỗi bounding box. Do không sử dụng region proposal nên kỹ thuật này có độ chính xác thấp hơn (ví dụ: nhiều lỗi định vị vật thể – localization error hơn), mặc dù hoạt động ở tốc độ 45 fps (khung hình / giây) và tối đa 155 fps cho phiên bản tối ưu hóa tốc độ. Tốc độ này còn nhanh hơn cả tốc độ khung hình của máy quay phim thông thường chỉ vào khoảng 24 fps.
Mô hình hoạt động bằng cách trước tiên phân chia hình ảnh đầu vào thành một lưới các ô (grid of cells), trong đó mỗi ô chịu trách nhiệm dự đoán các bounding boxes nếu tâm của nó nằm trong ô. Mỗi grid cell (tức 1 ô bất kì nằm trong lưới ô) dự đoán các bounding boxes được xác định dựa trên tọa độ x, y (thông thường là tọa độ tâm, một số phiên bản là tọa độ góc trên cùng bên trái) và chiều rộng (width) và chiều cao (height) và độ tin cậy (confidence) về khả năng chứa vật thể bên trong. Ngoài ra các dự đoán nhãn cũng được thực hiện trên mỗi một bonding box.
Ví dụ: một hình ảnh có thể được chia thành lưới 7 × 7 và mỗi ô trong lưới có thể dự đoán 2 bounding box, kết quả trả về 98 bounding box được đề xuất. Sau đó, một sơ đồ xác suất nhãn (gọi là class probability map) với các confidence được kết hợp thành một tợp hợp bounding box cuối cùng và các nhãn. Hình ảnh được lấy từ bài báo dưới đây tóm tắt hai kết quả đầu ra của mô hình.
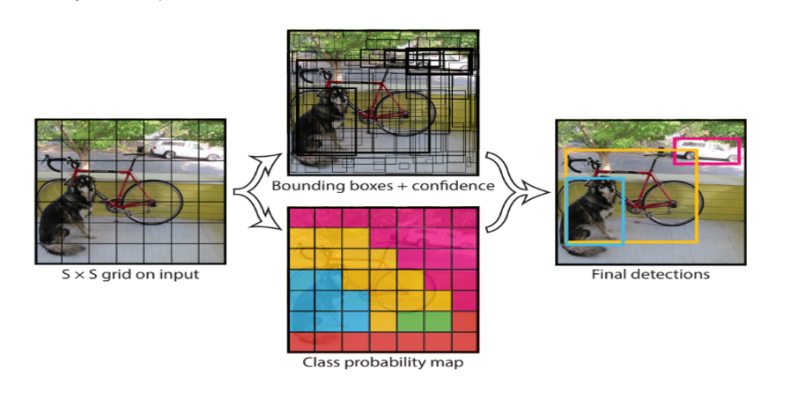
Hình 4 : Các bước xử lý trong mô hình YOLO.
Đầu tiên mô hình chia hình ảnh thành một grid search kích thước SxS. Trên mỗi một grid cell ta dự báo một số lượng B bounding boxes và confidence cho những boxes này và phân phối xác suất của C classes. Như vậy output các dự báo là một tensor kích thước S x S x (B x 5 + C). Giá trị 5 là các tham số của offsets của bounding box gồm x,y,w,h và confidence. C là số lượng tham số của phân phối xác suất.
Đề Xuất Giải Quyết Bài Toán Phát Hiện Đối Tượng
Faster R-CNN và YOLO là hai phương pháp đề xuất giải quyết bài toán object detection , bên cạnh đó chúng cũng đã đạt được sự phổ biến và thành công đáng kể trong cộng đồng computer vision.
Về nhận định ban đầu cả hai thuật toán đều có những ưu điểm và nhược điểm riêng, phù hợp với các yêu cầu cụ thể của ứng dụng.
Lựa chọn hướng giải quyết bằng Faster RCNN và YOLO là dựa trên các yếu tố sau:
- Tính khả thi: Cả hai thuật toán đều có thể được triển khai trên các máy tính có cấu hình thông thường.
- Độ chính xác: Faster RCNN là một thuật toán object detection chính xác, phù hợp với các ứng dụng đòi hỏi độ chính xác cao.
- Tốc độ thực hiện: YOLO là một thuật toán object detection nhanh, phù hợp với các ứng dụng yêu cầu thời gian thực.
Tuy nhiên cũng nhận định một số nhược điểm sẽ kiểm nghiệm trong thực nghiệm:
Faster RCNN có thời gian thực hiện chậm và yêu cầu nhiều bộ nhớ.
YOLO có độ chính xác thấp hơn Faster RCNN và khó phát hiện được các đối tượng nhỏ và có độ che khuất.
Phương Pháp Thực Hiện
Các Bước Thực Hiện
- Xử lý dữ liệu
Bước đầu tiên là xử lý dữ liệu. Dữ liệu cần được chuẩn hóa và đánh nhãn. Chuẩn hóa dữ liệu sẽ giúp cho mô hình học được các đặc trưng phổ biến của đối tượng. Đánh nhãn dữ liệu sẽ giúp cho mô hình biết được đối tượng nào có trong hình ảnh.
- Tối ưu hóa
- Huấn luyện mô hình
Bước thứ ba là đào tạo mô hình. Mô hình sẽ được đào tạo trên một tập dữ liệu được đánh nhãn. Trong quá trình đào tạo, mô hình sẽ được cập nhật các tham số để cải thiện độ chính xác của dự đoán.
- Tinh chỉnh
Sau khi đào tạo, mô hình có thể được tinh chỉnh để cải thiện độ chính xác hơn nữa. Tinh chỉnh mô hình có thể được thực hiện bằng cách sử dụng một tập dữ liệu tinh chỉnh.
- Dự đoán
Bước cuối cùng là dự đoán. Mô hình đã được đào tạo sẽ được sử dụng để dự đoán đối tượng trong các hình ảnh mới.
Đặc Trưng Của Thuật Toán
| Đặc trưng | Faster R-CNN | YOLO |
| Region Proposal | Có | Không |
| Fast R-CNN | Có | Không |
| Single Shot | Không | Có |
| MultiBox Detector | Không | Có |
| Tốc độ thực hiện | Chậm | Nhanh |
| Độ chính xác | Cao | Thấp hơn |
| Yêu cầu bộ nhớ | Nhiều | Ít |
Bảng 1: So sánh đặc trưng hai thuật toán
Thực Nghiệm
Dữ Liệu Thực Nghiệm
Bộ dữ liệu thực nghiệm: https://www.kaggle.com/datasets/huanghanchina/pascal-voc-2012
- Annotations: Thư mục này chứa các tệp nhãn cho các hình ảnh trong tập dữ liệu. Các tệp nhãn này cung cấp thông tin về các đối tượng được phát hiện trong mỗi hình ảnh.
- ImageSets: Thư mục này chứa các tệp danh sách các hình ảnh trong mỗi tập dữ liệu.
- Action: Thư mục này chứa các tệp nhãn cho các hành động được thực hiện bởi các đối tượng trong tập dữ liệu.
- Layout: Thư mục này chứa các tệp nhãn cho bố cục của các đối tượng trong tập dữ liệu.
- Main: Thư mục này chứa các tệp chính của tập dữ liệu, bao gồm tệp danh sách các hình ảnh trong bộ đào tạo, bộ kiểm tra và bộ phát triển.
- Segmentation: Thư mục này chứa các tệp nhãn cho phân đoạn của các đối tượng trong tập dữ liệu.
- JPEGImages: Thư mục này chứa các hình ảnh trong tập dữ liệu.
-
SegmentationClass: Thư mục này chứa các tệp nhãn cho phân đoạn của các đối tượng trong tập dữ liệu, được biểu thị dưới dạng các lớp đối tượng.
-
SegmentationObject: Thư mục này chứa các tệp nhãn cho phân đoạn của các đối tượng trong tập dữ liệu, được biểu thị dưới dạng các đối tượng cụ thể.
- Định dạng dữ liệu đầu vào: Các mô hình YOLO và Faster R-CNN thường yêu cầu dữ liệu đầu vào có một định dạng cụ thể. Điều này bao gồm việc chuyển đổi hình ảnh và bounding boxes thành định dạng được mô hình yêu cầu. Ví dụ, YOLO thường yêu cầu đầu vào dưới dạng các hình ảnh có kích thước cố định và các tệp tin XML chứa thông tin bounding boxes.
- Xử lý bounding boxes: Bounding boxes chứa thông tin về vị trí và loại của đối tượng trong ảnh. Trước khi đào tạo, bạn cần đảm bảo rằng các bounding boxes đã được chuẩn hóa và có định dạng đúng. Điều này có thể bao gồm việc chuyển đổi các tọa độ, chuẩn hóa kích thước, và mã hóa các nhãn của các đối tượng.
- Data augmentation (Tăng cường dữ liệu): Tăng cường dữ liệu là một phần quan trọng của việc chuẩn bị dữ liệu. Nó giúp tăng sự đa dạng của dữ liệu huấn luyện và cải thiện khả năng tổng quát hóa của mô hình. Các phép biến đổi thường bao gồm phép xoay, phép phóng to, phép thu nhỏ, phép lật ảnh, và thậm chí là việc thêm nhiễu vào ảnh.
- Chuẩn hóa dữ liệu: Trong một số trường hợp, việc chuẩn hóa dữ liệu là cần thiết để đảm bảo rằng giá trị pixel của ảnh nằm trong khoảng [0, 1] hoặc [-1, 1]. Điều này giúp mô hình học tốt hơn.
- Chọn các phân lớp (classes): Bạn cần xác định các lớp (classes) cần phát hiện trong dữ liệu và đảm bảo rằng mô hình của bạn đã được cấu hình để phân lớp chính xác.
-
Xử lý trọng số (weights) cho mô hình: Trong một số trường hợp, bạn có thể xác định trọng số cho các lớp hoặc các ảnh cụ thể để điều chỉnh sự quan trọng của chúng trong quá trình đào tạo.
-
Chia nhỏ dữ liệu thành các batch: Dữ liệu thường được chia thành các batch nhỏ hơn để đào tạo mô hình một cách hiệu quả hơn.
-
Sử dụng các DataLoader: Các DataLoader trong PyTorch hoặc các thư viện tương tự giúp bạn quản lý việc nạp dữ
-
Chia thành tập huấn luyện và tập kiểm tra: Bộ dữ liệu PASCAL VOC 2012 được chia thành ba phần chính: tập huấn luyện và tập kiểm tra, tập Validation. Tập huấn luyện được sử dụng để đào tạo mô hình, tập validation sử dụng đánh giá hiệu xuất, tránh overfitting, trong khi tập kiểm tra được sử dụng để đánh giá hiệu suất của mô hình sau khi đào tạo.
Chạy Thực Nghiệm
Thực hiện chạy trên máy ảo cài đặt Ubuntu và các thư viện hỗ trợ Python
Đường dẫn tải code tại đây
Phương Pháp Đánh Giá
Đánh giá mô hình Object Detection thông qua Precision và mAP là một quá trình quan trọng để đánh giá hiệu suất của mô hình trong việc phát hiện và phân loại các đối tượng trong hình ảnh.
Precision (Độ chính xác):
Precision là chỉ số đo lường khả năng của mô hình trong việc đưa ra dự đoán chính xác về đối tượng. Nó đo lường tỷ lệ giữa số lượng đối tượng dự đoán đúng (True Positives) trên tổng số lượng đối tượng được dự đoán là đúng (True Positives và False Positives). Precision thường được tính trên mỗi lớp đối tượng riêng biệt.
Công thức tính Precision cho một lớp đối tượng:
Precision= True Positives/(False Positives+True Positives)
Trong đó:
Các bước để tính mAP:
- Sắp xếp các dự đoán của mô hình theo điểm số (confidence score) giảm dần.
- Tính Precision cho mỗi dự đoán tại các ngưỡng IoU khác nhau (thông thường từ 0.5 đến 0.95).
- Vẽ đường Precision-Recall cho mỗi lớp đối tượng.
- Tính diện tích dưới đường Precision-Recall curve bằng cách sử dụng phương pháp tích phân (trapezoidal rule) cho mỗi lớp đối tượng.
- Lấy trung bình của diện tích này trên tất cả các lớp đối tượng để có giá trị mAP tổng thể.
- mAP thường được sử dụng để đánh giá hiệu suất tổng thể của mô hình Object Detection trên toàn bộ tập dữ liệu và cho biết mức độ nhạy cảm của mô hình đối với việc xác định và phân loại các đối tượng.
Trong ngữ cảnh Object Detection, Precision giúp đánh giá độ chính xác cụ thể cho mỗi lớp đối tượng, trong khi mAP cung cấp một cái nhìn tổng thể về hiệu suất của mô hình trên tất cả các lớp đối tượng và các ngưỡng IoU khác nhau.
Kết Quả & Đánh Giá
| Số epochs | Thuật toán | Thời gian thực hiện | Độ chính xác | mAP |
| 15 | Faster R-CNN | 17h 42m 3s | 58.08% | 0.44 |
| 15 | YOLO | 4h 24m 05s | 44,42% | 0.14 |
Nhận xét và đánh giá:
Kết Luận